

智东西9月12日报道,今天凌晨,阿里通义实验室正式发布下一代基础模型架构Qwen3-Next,并训练了基于该架构的Qwen3-Next-80B-A3B-Base模型,该模型拥有800亿个参数,仅激活30亿个参数。
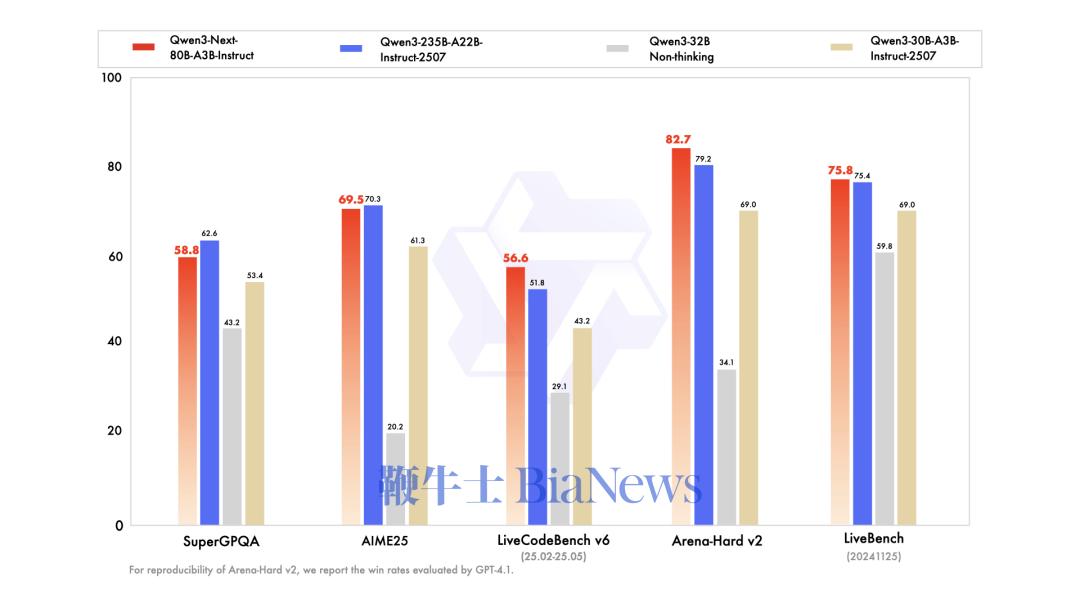
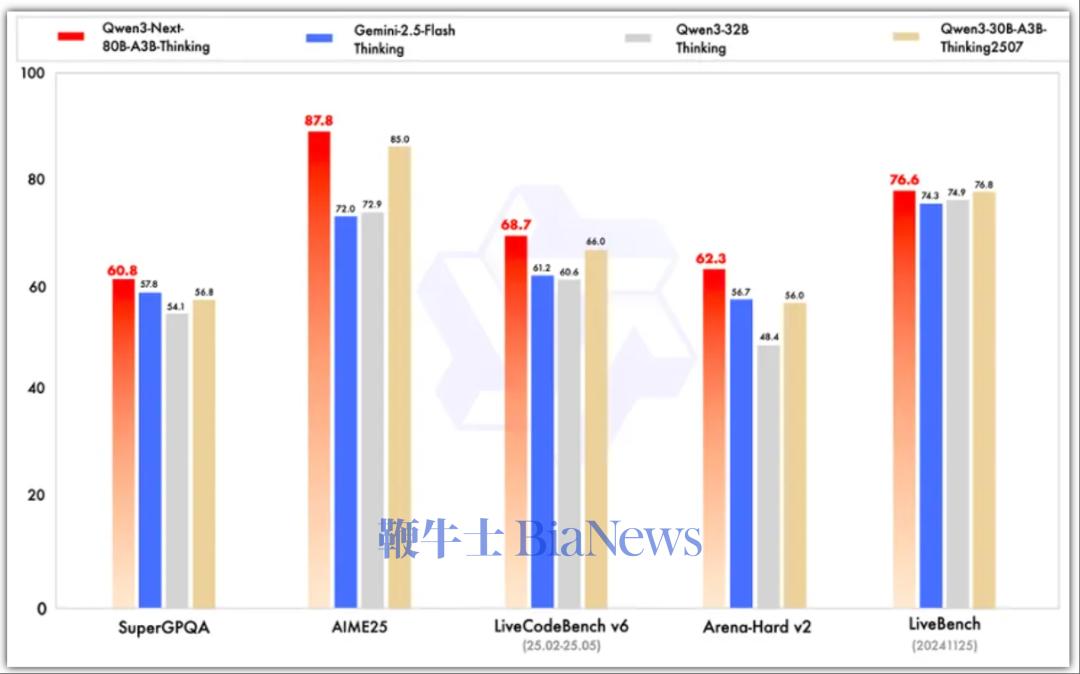
其中,Qwen3-Next-80B-A3B-Instruct仅支持指令(非思考)模式,其输出中不生成<think></think>块;Qwen3-Next-80B-A3B-Thinking仅支持思考模式,为了强制模型进行思考,默认聊天模板自动包含<think>。 指令模型的性能表现与参数规模更大的Qwen3-235B-A22B-Instruct-2507相当,思维模型优于谷歌闭源模型Gemini-2.5-Flash-Thinking。
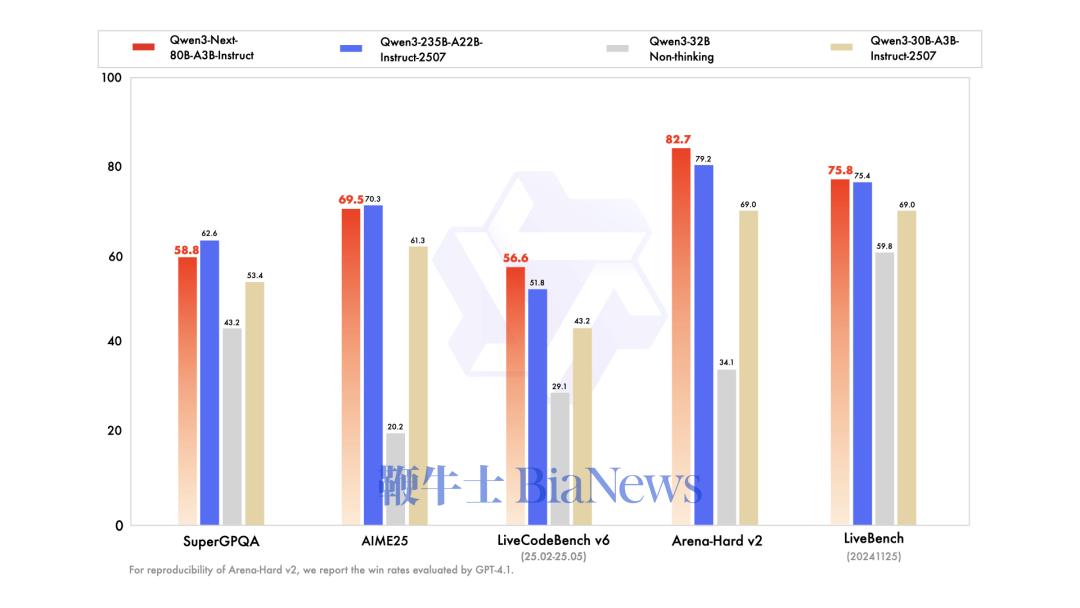
▲指令模型测试基准
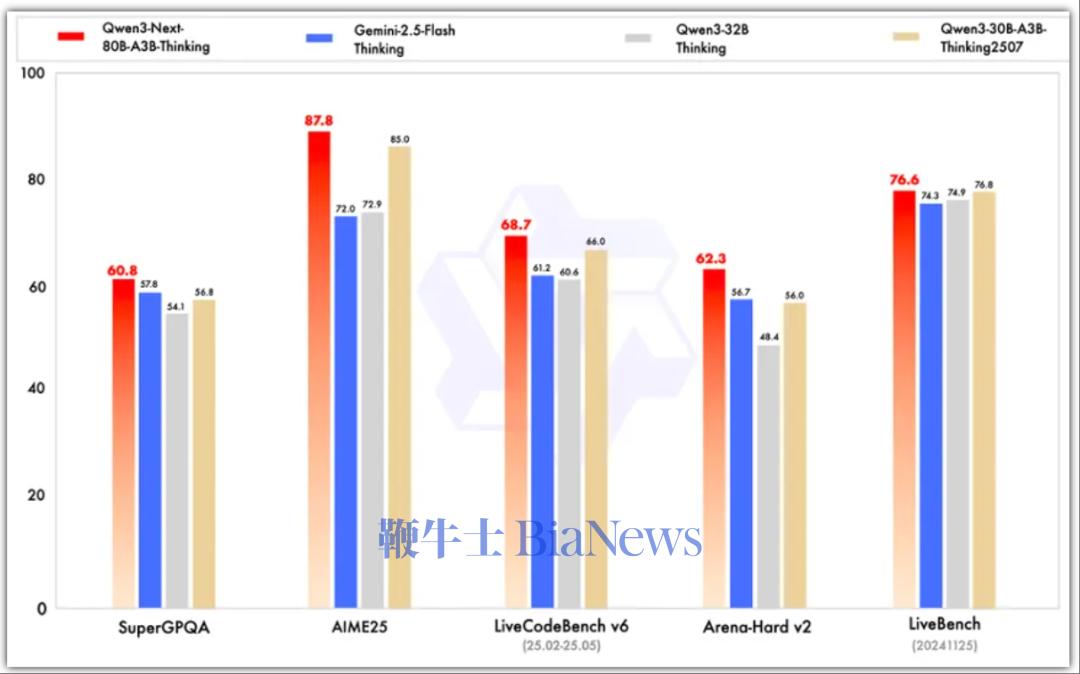
▲思维模型测试基准

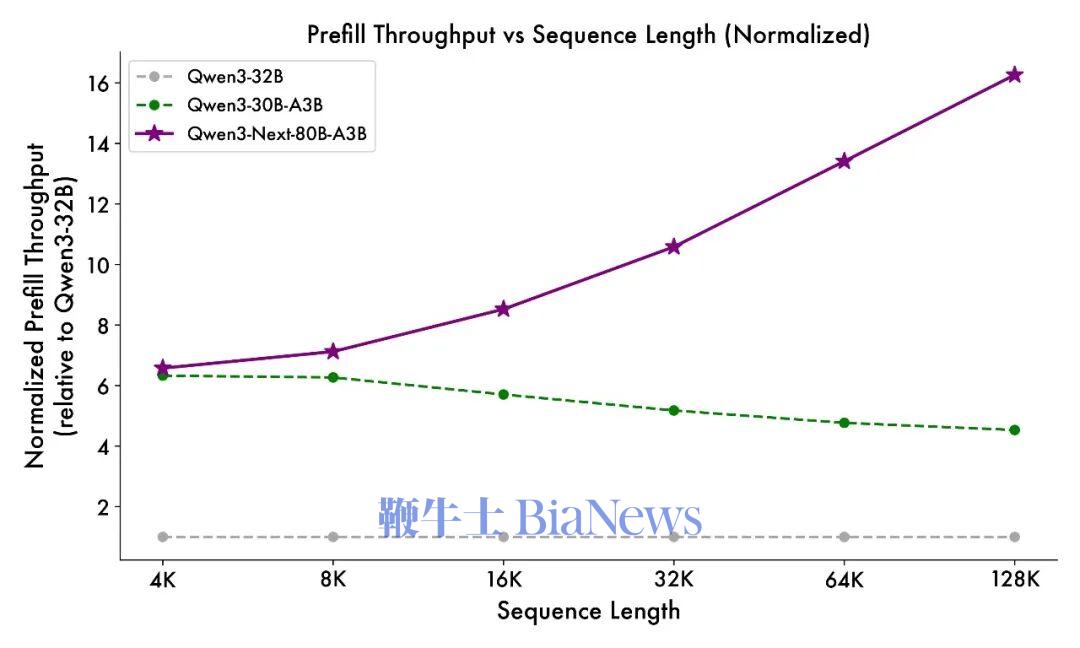
总的来看在性能方面,指令模型接近阿里参数规模235B的旗舰模型,思维模型表现优于Gemini-2.5-Flash-Thinking。 得益于其新的混合模型架构,Qwen3-Next在推理效率方面,与Qwen3-32B相比,Qwen3-Next-80B-A3B在预填充(prefill)阶段,在4k tokens的上下文长度下,吞吐量接近前者的7倍,当上下文长度超过32k时,吞吐量提升达到10倍以上。 在解码(decode)阶段,该模型在4k上下文下实现近4倍的吞吐量提升,在超过32k的长上下文场景中能保持10倍以上的吞吐优势。 具体来看,其指令模型表现优于Qwen3-30B-A3B-Instruct-2507和Qwen3-32B-Non-thinking,并取得了几乎与参数规模更大的Qwen3-235B-A22B-Instruct-2507模型相近的结果。 只有在面向大模型的综合性评测基准、高难度数学推理基准AIME25中,指令模型的表现略逊色于Qwen3-235B-A22B-Instruct-2507,在编程、复杂问答与长对话的评测中表现更好。 Qwen3-Next-80B-A3B-Instruct在RULER上所有长度的表现明显优于层数相同、注意力层数更多的Qwen3-30B-A3B-Instruct-2507,甚至在256k范围内都超过了层数更多的Qwen3-235B-A22B-Instruct-2507。 思维模型的表现优于预训练成本更高的Qwen3-30B-A3B-Thinking-2507、Qwen3-32B-thinking,全面超过谷歌的闭源模型Gemini-2.5-Flash-Thinking,并在部分指标上接近阿里最新旗舰模型Qwen3-235B-A22B-Thinking-2507。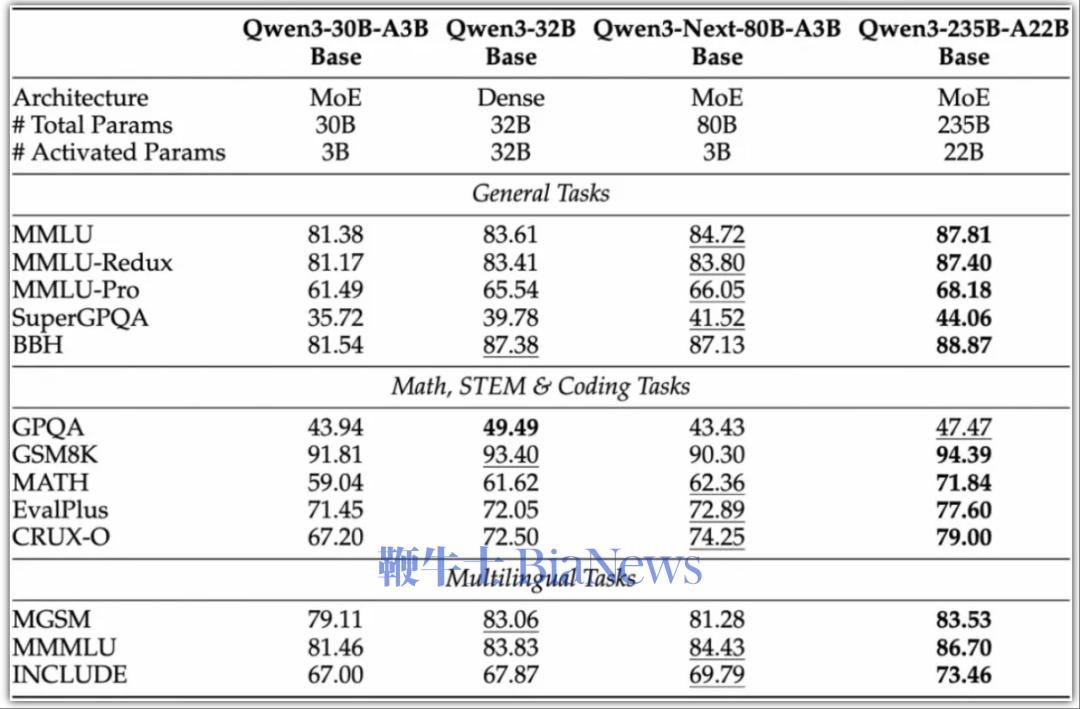


研究人员在博客中提到,Qwen3-Next是针对大模型在上下文长度和总参数两方面不断扩展的未来趋势而设计。 Qwen3-Next采用的是Qwen3 36T预训练语料的均匀采样子集,包含15T tokens的训练数据,其训练所消耗的GPU Hours不到Qwen3-30A-3B的80%;与Qwen3-32B相比,仅需9.3%的GPU计算资源,即可实现更优的模型性能。 这一模型结构相较其4月底推出的Qwen3的MoE模型,新增了多种新技术并进行了核心改进,包括混合注意力机制、高稀疏度MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多Token预测(MTP)机制等。 混合注意力机制:用Gated DeltaNet(线性注意力)和Gated Attention(门控注意力)的组合替换标准注意力,实现超长上下文长度的有效上下文建模。 同时在保留的标准注意力中,研究人员进一步引入多项增强设计,包括沿用先前工作的输出门控机制,缓解注意力中的低秩问题,将单个注意力头维度从128扩展至256,仅对注意力头前25%的位置维度添加旋转位置编码,提高长度外推效果。 高稀疏度混合专家(MoE):在MoE层中实现极低的激活比率,大幅减少每个token的FLOPS,同时保留模型容量。研究人员的实验表明,在使用全局负载均衡后,当激活专家固定时,持续增加专家总参数可带来训练loss的稳定下降。 稳定性优化:包括零中心化和权重衰减LayerNorm等技术,以及其他增强稳定性以实现鲁棒的预训练和后训练。研究人员发现,注意力输出门控机制能消除注意力池与极大激活等现象,保证模型各部分的数值稳定。 多Token预测(MTP):提升预训练模型性能并加速推理,Qwen3-Next特别优化了MTP多步推理性能,通过训练推理一致的多步训练,进一步提高了实用场景下的投机采样(Speculative Decoding)接受率。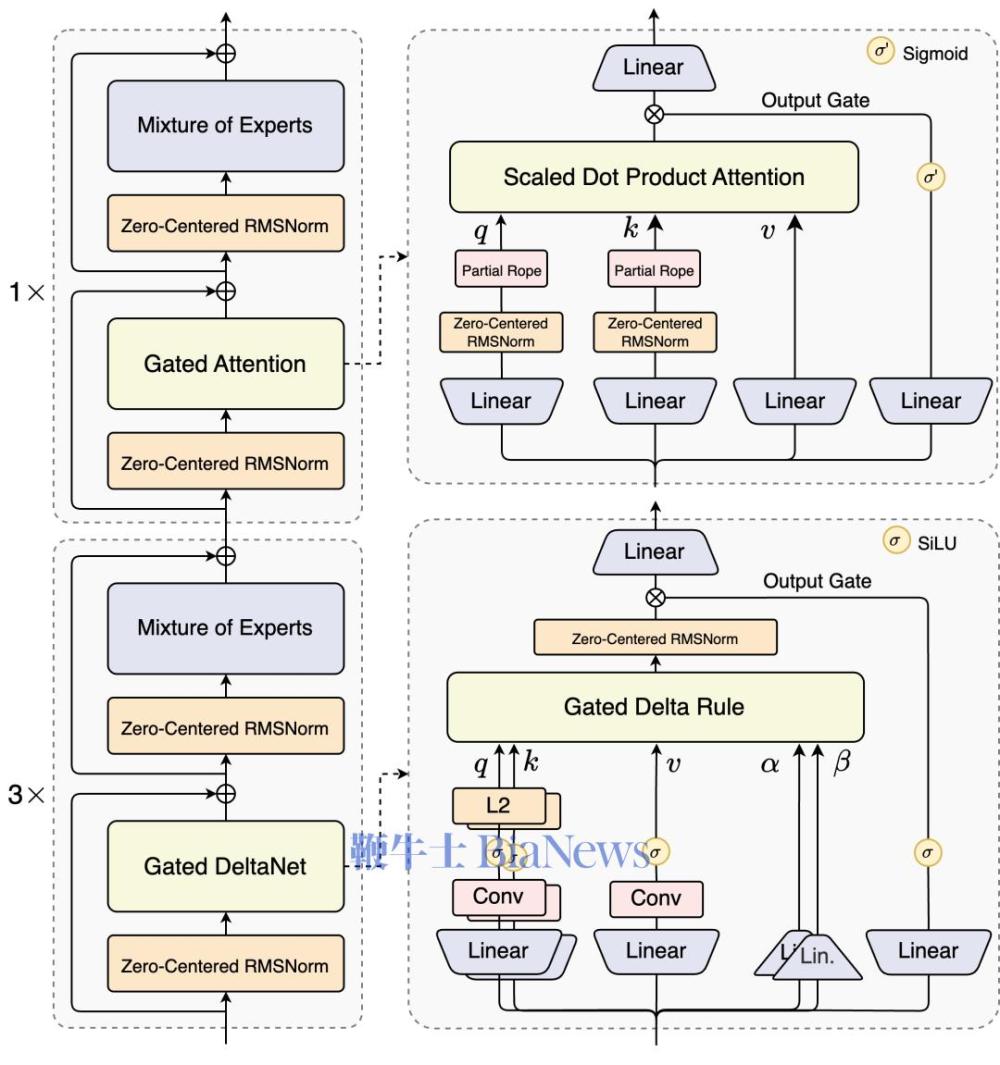
Qwen3-Next的突破点在于同时实现了大规模参数容量、低激活开销、长上下文处理与并行推理加速。此外结合注意力机制、MoE设计等方面的多项架构创新,阿里通义此次实现仅激活3B参数模型就能对标规模更大模型的性能,使得模型在性能与效率之间找到更佳平衡点,同时为降低模型训练、推理成本提供了有效路径。
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



