

2023年夏天,当颜水成与 Yann LeCun 并肩站在北京智源大会的聚光灯下,向台下数百名中国 AI 核心研究者阐述 JEPA时,LeCun 刚刚在 Meta 内部经历了一场关乎技术主权的漫长博弈。
彼时,大语言模型正以狂暴的姿态横扫硅谷,"Scaling Law"被奉为通往 AGI 的唯一信仰。LeCun 在 FAIR 内部强推世界模型时,曾有资深研究员直言不讳地反驳:“试图让机器通过自监督学习获得物理常识,可能还要再等上半个世纪。”而几乎在同一时间,他的老友、也是学术宿敌的李飞飞,正隐于喧嚣之外筹备 World Labs。坊间传闻,两人在一次私下通话中曾半开玩笑地约定:如果世界模型五年内没有任何突破性进展,就一起回高校学术界去“养老”。
然而,AI 范式的迭代速度击碎了所有保守的预言。
仅仅两年后,李飞飞的 World Labs 便以“空间智能”高调切入,重新定义了 3D 神经世界的交互边界;LeCun 执着闭门造车的 JEPA 架构,开始被越来越多的硬核工业界团队奉为底层圭臬;当年在智源大会上向他犀利发问的颜水成,带着林敏等一众“颜家军”核心骨干,在全认知世界模型与多模态大一统 Backbone 的亿级用户场景中,完成了静默而凶猛的工程验证;在英伟达圣克拉拉总部,Jim Fan 带领的 GEAR 实验室正将 Voyager 的终身自主学习经验推向工业级物理 AI——Cosmos 的雏形已在芯片巨头的算力底座上悄然成型。
相比于位学术宗师的声名起落,这段学术理想与产业现实肉搏的历程,带给整个行业最大的启示,是对技术周期的重新审视:那些真正能够调转历史车头的关键拐点,往往在主流最喧嚣的缝隙中,就已经蛰伏了很久。
当大语言模型的降维狂欢逐渐退潮,行业对“世界模型才是通往物理自主智能(Autonomous Intelligence)终局战场”的共识正迅速凝聚。但共识之下,关于“世界模型究竟该长什么样”的底层哲学分歧,才刚刚暴露出最锋利的刀刃。
而在这些大宗师的身后,一张由全球顶尖华人青年学者交织而成的智力网络,正以惊人的代码吞噬力和工程穿透力,将这场宏大的范式博弈,翻译成前线最硬核的算法、实验与工业地基。
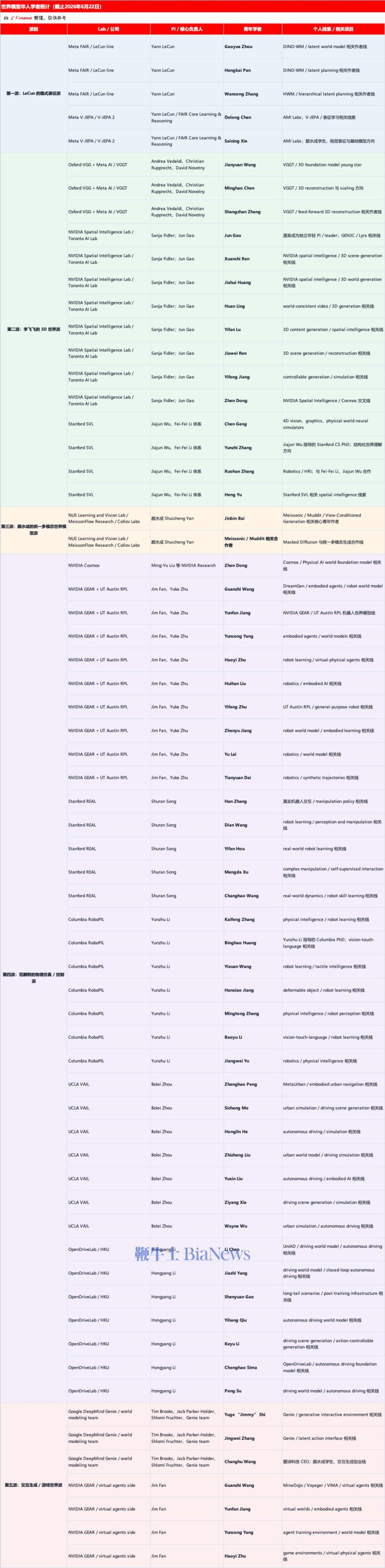
第一派:LeCun 的隐式表征派(The Latent Representation School)
这是世界模型的“认知科学派”,亦被许多研究者奉为“智能体正统派”。它本质上在回答一个根本性的哲学与科学问题:人工智能是否必须像人类一样,在脑海中形成一个无需流于表面细节、却能完美推演规律的抽象世界?
隐式表征派的旗帜上写着一行醒目的大字:世界模型不应该执着于重建像素。
在 Yann LeCun 看来,传统视频生成模型(如 Sora 或主流 Diffusion 模型)花费了海量的算力去预测视频中的下一个像素是什么、斑马的条纹如何抖动、或者背景中的树叶怎么随风飘落。这种对绝对视觉细节的追求,在认知科学上是极度低效且不符合人类直觉的。人类在驾车时,大脑并不会去精准计算路边每一朵花的颜色变化,而是抽象出“道路”、“行人”、“障碍物”这些高阶概念,并在一个“隐空间(Latent Space)”中预测它们的轨迹和交互。
因此,这一派坚信,世界模型的核心应该在于Action-Conditioned Prediction(基于行动条件的状态预测)。模型通过自监督学习,将复杂的视觉信号压缩进隐空间,并在该空间内根据智能体可能采取的动作,预测世界下一步的抽象状态。它的终极目的不是为了生成一段逼真的好莱坞大片,而是为了支持智能体(Agent)进行高效的预测、规划与行动。
这一路线的绝对大本营是Meta FAIR(基础人工智能研究研究院)。其核心技术演进可以用以下几项里程碑式的工作来勾勒:
•JEPA (Joint Embedding Predictive Architecture): 联合嵌入预测架构。这是 LeCun 对抗自回归架构的核武器,通过比较预测的表征而不是预测像素本身,避免了生成模型的坍塌问题。
•V-JEPA 与 V-JEPA 2: 将 JEPA 架构完美应用于视频领域,展示了模型在不依赖文本提示词、不依赖生成像素的情况下,仅通过隐空间特征就能展现出对物理世界物体运动、遮挡、重力等规律的深刻理解。
•DINO-WM 与 HWM (Hierarchical World Models): 进一步引入分层设计的世界模型,让智能体不仅能预测下一秒发生的事(低阶控制),还能在隐空间中规划未来几分钟甚至几小时的长期行为(高阶决策)。
代表作者
谢赛宁(Saining Xie)
作为纽约大学(NYU)计算机科学助理教授、Courant 研究所核心成员,谢赛宁是当前全球生成式 AI 领域的超级新星与殿堂级青年宗师。他本科毕业于上海交通大学,在加州大学圣迭戈分校(UCSD)取得博士学位,师从视觉领域泰斗级华人学者。在大模型时代,他是无可争议的“视觉 Backbone 架构师”——作为共同第一作者,他与已故天才科学家 Bill Peebles 合作提出了重磅里程碑架构 DiT(Diffusion Transformers)。这一工作彻底打破了传统 U-Net 的局限,首次将 Transformer 架构引入扩散模型中,直接成为了 OpenAI Sora、可灵等全球主流视频大模型的核心底层底层地基。
在世界模型的科学分歧中,谢赛宁处于隐式表征派与视觉生成的黄金交叉点。他的研究不仅关注如何让 AI 生成高保真的像素画面,更深刻聚焦于视觉模型内部的结构可解释性与其所蕴含的物理、语义常识。在近期针对世界模型(World Models)与具身智能的前沿探索中,谢赛宁团队深入研究了多模态表征空间、视觉自监督学习以及高效的潜空间(Latent Space)可控预测机制。作为 Yann LeCun 执教的 NYU 同系学者,谢赛宁的一系列突破性架构,正在为“世界模型如何在脑中高效率、高保真地推演并预测物理世界的未来走向”提供最坚实的 Backbone 动力。

陈德龙 (Delong Chen)
陈德龙目前是香港科技大学与高级机器智能实验室(AMI Labs)的在读博士生,并在 2024 年至 2026 年期间以访问学者身份深度扎根于巴黎的 Meta FAIR 团队。在世界模型的语境下,他是坚定的“非像素重建”路线践行者,其研究重心直指一个核心痛点:如何在完全不依赖高成本像素解码器的前提下,让模型在隐空间内对复杂的跨模态因果关系进行准确的语义预测。
他在 2026年 ICLR 斩获 Oral 获评的里程碑工作 VL-JEPA (Joint Embedding Predictive Architecture for Vision-language),直接将 Yann LeCun 的联合嵌入预测架构从纯视觉推向了“视觉-语言”联合空间。他的工作证明了通过精妙的对比学习与掩码设计,隐式世界模型不仅能看懂画面,更能以极低的算力成本在隐空间中推演出未来语义的演变趋势。
此外,针对世界模型的评估难题,陈德龙主导推出了WorldPrediction 这一大范围视频基准。不同于以往关注机器人底层动作控制的测试,这一基准强调时间与语义层面的高级抽象。通过去除背景低级像素的干扰,它能精准测试 AI 模型的“内部世界模型”是否具备和人类一样的长程程序性规划能力。

张万聪 (Wancong Zhang)
张万聪是纽约大学 Courant 研究所的博士生,直接导师便是 Yann LeCun 教授,同时他也在 Meta FAIR 担任研究科学家实习生。张万聪的整个学术主线围绕着世界模型、表征学习与无奖励(Reward-Free)数据下的智能体决策展开,他致力于解决隐式世界模型在面对长期复杂任务时“理解深刻但难以进行长程推理和控制”的瓶颈。
在具身智能的理论突破上,张万聪作为第一作者在 NeurIPS 2025 发表了关于利用潜在动力学模型(Latent Dynamics Models)从无奖励离线数据中进行学习的成果,并斩获了 ICML 2025 物理合理世界模型研讨会的“最佳论文奖”。该工作证明了在没有任何奖励引导的轨迹数据中,基于 JEPA 架构训练的零样本规划(Zero-shot Planning)在泛化性、轨迹拼接和数据效率上,都显著优于传统的离线强化学习。
进入 2026 年,他进一步推出了 Hierarchical Planning with Latent World Models 这一硬核突破。该研究通过在多个时间尺度上构建分层潜在世界模型,让智能体既能处理低阶动作,又能理解长程逻辑,在机器人和模拟控制任务中大幅削减了规划时的计算开销,是 LeCun 理论走向实用化的重要里程碑。

潘恒楷 (Hengkai Pan)
潘恒楷活跃于顶尖计算机视觉与具身智能的研究交汇处,他的核心研究方向是视觉自监督表征的鲁棒性以及在物理噪声环境下的未来视频预测。在世界模型的落地过程中,传统生成模型经常被现实世界中无数与决策无关的随机噪音(例如风吹树叶的抖动、光影错落的变化)牵扯海量算力,甚至导致整个重建系统崩溃。
潘恒楷正是解决这一痛点的关键推手。他通过引入先进的时空掩码机制与特征不变性约束,帮助世界模型在隐空间中自动过滤高频物理噪音,只捕获最本质的物体拓扑结构与动态轨迹。
在 2026 年的具身世界模型前沿探索中,潘恒楷作为共同作者推出了名为 ViPRA (Video Prediction for Robot Actions) 的研究工作,并在相关顶级研讨会上做 Oral 汇报。这项工作将动作条件(Action Condition)深度织入视频预测,为机器人动作规划提供了紧凑且具备物理一致性的预测环境,直接增强了隐式世界模型在开放、动态现实世界中对抗不确定性的实用价值。

Gaoyue Zhou
Gaoyue 的学术路径是一条从数学与计算机科学交叉点出发、逐步深入具身智能核心的典型轨迹。她本科毕业于加州大学伯克利分校(UC Berkeley),获计算机科学与应用数学双学位;随后在卡内基梅隆大学机器人研究所(CMU Robotics Institute)取得机器人学硕士学位;现为纽约大学柯朗数学科学研究所(NYU Courant)计算机科学博士在读,师从具身智能领域核心人物 Lerrel Pinto 与 Yann LeCun,研究方向聚焦于机器人学、强化学习与自然语言处理的交叉地带。
在 LeCun 的整体愿景中,世界模型的终极目的是作为具身智能体(Embodied Agent)的大脑,用于在脑海中模拟不同动作带来的物理反馈。周高月的研究正是这一链条上的关键闭环。她参与的 Real World Offline Reinforcement Learning with Realistic Data Sources 等工作,深入探讨了当训练数据“不够完美、充满噪音”时,智能体如何借助潜在物理世界的因果规律进行稳健的学习。

第二派:李飞飞的 3D 世界派
这是世界模型的“空间智能派”。它把 AI 从“看见图像”的二维平面,彻底推进到“理解空间”的三维物理世界,构成了李飞飞从 ImageNet 时代(像素认知)走向 World Labs 时代(空间主权)的进化主线。
这一派认为,如果世界模型只能像 Sora 一样生成一帧帧扁平的像素视频,那它并没有真正理解这个世界。一个合格的世界模型,必须理解物理世界的空间几何、光影变化以及相机的相对运动。
World Labs 推出的旗舰大模型 Marble 以及开放的 World API 正是这种理念的具现:它不是生成一段不可控的死视频,而是生成一个可移动、可编辑、可进入的 3D 虚拟现实空间,用户或 AI Agent 可以在其中任意改变视角并与之交互。与此同时,学术界的 VGGT 路线则代表了 3D 视觉大模型的另一种硬核解法——不走弯路,直接让模型去预测和推算三维空间的 Camera 轨迹、Point map(点云图)、Depth(深度)以及 3D tracks(三维运动轨迹)。
代表机构
•World Labs: 李飞飞亲自下场创办的具身智能与空间智能独角兽,也是该流派当前的产业先锋。
•Stanford SVL(斯坦福视觉与学习实验室): 这一学派的精神大本营,源源不断地向工业界输出核心技术与顶级 PhD。
•Oxford VGG + Meta AI / VGGT: 联合学术线,主攻 3D 基础模型(3D Foundation Model)的底层算法攻坚。
•NVIDIA Spatial Intelligence Lab(英伟达空间智能实验室): 掌握着算力和图形学底座,从硬件和仿真环境端深度布局 3D 空间主权。
代表学者
吴佳俊(Jiajun Wu)
作为斯坦福大学计算机科学与心理学助理教授,以及李飞飞在斯坦福视觉与学习实验室(SVL)最核心的长期合作者,吴佳俊被普遍视为该流派青年学者中的领军旗帜。他本科毕业于清华大学姚班,随后在麻省理工学院(MIT)取得博士学位。他的研究特色在于打破了单纯的“数据驱动型视觉”,将神经物理学(Neural Physics)、三维几何结构与计算认知科学融为一体。
吴佳俊极其擅长让 AI 具备像人类一样的“物理直觉”——不仅能看出物体的形状,还能在脑中推算物体的力学质量、重心以及受到外力后的运动趋势。这种让大模型理解真实物理法则的算法天赋,使他成为当前连接视觉空间智能与具身智能机器人(Robot Learning)不可或缺的底层推手。

王建元(Jianyuan Wang)
王建元是牛津大学视觉几何组(Visual Geometry Group, VGG)与 Meta AI(FAIR 实验室)联合培养的博士,是当前国际 3D 视觉大模型领域的超级新星。在学术界,他凭借第一作者的身份,带领团队凭借论文《VGGT: Visual Geometry Grounded Transformer》斩获了计算机视觉顶级会议 CVPR 2025 的最佳论文奖(Best Paper Award)。他主导的 VGGT 与最新的升级版 VGGT-
路线,代表了空间智能派极其硬核的纯前馈 3D 重建方向:直接让大模型通过一幅或几幅非标定视角的 2D 画面,瞬间预测出相机的运动参数、场景的深度图、点云图以及三维运动轨迹。这一突破直接跳过了传统复杂的计算步骤,为 3D 世界模型构建了实时感知空间的底层地基。

陈明豪(Minghao Chen)
陈明豪同样是活跃于牛津大学 VGG 实验室与顶级 AI 生态中的中坚青年学者,长期致力于 3D 生成、多视图扩散模型以及场景解构的研究。在 2026 年初,他作为核心推动者联合发布了名为 PointWorld 的大规模预训练 3D 世界模型,在学术界引发重磅反响。PointWorld 的核心贡献在于,它将机器人的“动作”与世界的“状态”统一在了一个共享的 3D 空间里(即三维点流 3D point flows)。通过输入少量的 RGB-D 图像和一段机器人操作指令,陈明豪参与构建的模型就能直接在三维几何层面上精准预测出全场景(包括机器人本体和物体)的运动形变和接触力学。他的研究让空间智能直接服务于开放世界中的通用机器人抓取与复杂交互。

高军(Jun Gao)
高军是英伟达空间智能实验室(NVIDIA Spatial Intelligence Lab)及多所顶尖研究机构的核心研究员,深度参与了英伟达在“空间主权”与虚拟环境仿真上的底层算法攻坚。高军的研究跨越了 3D 场景重建、多智能体交互仿真以及机器人触手(Affordance)基础模型。在进入 2026 年后,他的最新工作(如 AFUN 等功能性理解模型)着重于解决空间智能在真实世界落地中的“飞点”和多义性Artifact。他通过为 3D 生成和渲染引入更符合物理规律的混合密度表征,让 AI 模型生成的 3D 场景具备极高的几何一致性与物理严密性,能够支持 4 个以上的虚拟智能体或机器人在同一个生成的 3D 共享空间里无缝、低延迟地进行多玩家交互与运动推演。

于恒(Heng Yu)
于恒是斯坦福大学计算机视觉与具身智能方向的博士生青年研究者,研究聚焦于 3D/4D 世界建模、动态场景生成、人物交互建模以及视频-动作闭环世界模型。他的研究主线与“空间智能”从二维视觉理解走向三维物理世界、可控生成和具身交互的发展趋势高度契合。他的 4Real 工作探索了从文本生成照片级 4D 动态场景的技术路径,使 AI 能够生成具有空间结构、时间演化和多视角一致性的动态世界;SocialGen 和 AnyLift 则进一步面向多人交互、人体动作与物体交互关系建模,探索如何从语言、视频和互联网视觉数据中提炼可用于世界模型训练的 3D 行为监督信号。
在视频-动作世界模型方向,他参与推进的 OpenWAM 尝试统一建模 video/action 的双向关系,使模型既能基于动作预测未来视觉变化,也能从视频变化中反推潜在动作。这一系列工作共同指向同一个目标:让世界模型从“生成和观看视觉内容”,走向能够理解三维空间、建模动态过程,并支持动作交互与因果推演的下一代可交互 AI 系统。

耿琛(Chen Geng)
作为斯坦福大学计算机科学博士项目(由吴佳俊与李飞飞联合指导)的优秀少壮派代表,耿琛正处于大模型向 3D 空间和物理世界升维的学术最前沿。他的工作专注于神经渲染(Neural Rendering)、神经辐射场(NeRF)以及三维高斯泼溅(3D Gaussian Splatting)等前沿图形学算法在世界模型中的新型应用。在李飞飞所倡导的“空间智能”体系下,耿琛等青年力量的研究核心在于如何克服“物理世界的数据荒原”。他们通过开发更高效的前馈三维重建架构,试图让机器人或 AR 边缘端设备在完全没有去过的新场景中,仅凭一眼就能在几毫秒内将残缺的平面视野“脑补”并渲染出高保真、可任意探索的三维物理世界,为具身智能的快速泛化清空障碍。

第三派:颜水成的统一多模态世界模型派
这是世界模型的“统一生成派”。它不同于 LeCun 更偏向于隐式表征与动作规划的路线,也不同于 World Labs 执着于 3D 空间重建的路线,而是立足于多模态生成 backbone 的底层重构。它的独特价值在于,为未来需要同时处理文本、图像、视频、视角、空间和动作交互的通用 AI,提供一种大一统的端到端生成架构。
这一派的核心哲学认为,世界模型不一定非要从精密的 3D 几何或机器人控制切入,完全可以通过升级多模态生成的底层 Backbone,来实现对现实世界的感知与模拟。他们选择用 Masked Diffusion(掩码扩散)、Discrete Diffusion(离散扩散)以及非自回归生成(Non-autoregressive Generation)架构,来重构传统的视觉生成范式。
在这一路线上,Meissonic 的诞生证明了 Masked Generative Transformer 可以在保持极高高分辨率图像生成质量的同时,拥有远超主流 Diffusion 模型的并行推理效率。而最新的 Muddit 模型则更进一步,将这条路线从单一的图像生成真正扩展到统一多模态生成,试图打造一个面向文本、图像、跨模态任务流的离散扩散 Backbone。在这一派的愿景中,当模型的架构足够通用、吞吐效率足够高、多模态对齐足够完美时,它自然就成为了一个能够包罗万象、实时推演现实变化的统一世界模型。
代表机构与学术阵营
•NUS Learning and Vision Lab(新加坡国立大学学习与视觉实验室): 颜水成教授学术思想的重要发源地和人才摇篮,长期在计算机视觉与表示学习领域引领前沿。
•MeissonFlow Research: 专注于下一代高效非自回归生成模型、Masked Diffusion 架构攻坚的前沿研究网络。
代表人物
颜水成(Shuicheng Yan)
颜水成教授是全球计算机视觉与多媒体领域的泰斗级宗师,国际计算机学会(ACM)、国际电气与电子工程师学会(IEEE)等五院院士。他长期横跨视觉 AI、表示学习、多媒体理解以及 e-AGI(生态通用人工智能)等多个前沿领域。作为华人视觉智能学派的殿堂级代表人物,颜水成不仅在学术界拥有数十万的恐怖引用量,更具备极强的产业操盘经验。在大模型时代,他敏锐地捕捉到了生成式 Backbone 变革的底层趋势,通过指导和联合多所顶尖实验室,将学术触角伸向了“统一多模态生成”的最前沿。他的存在,为这一派系提供了高屋建瓴的范式视野与强大的资源磁吸力。

白晋斌(Jinbin Bai)
白晋斌是新加坡国立大学(NUS)与 MeissonFlow Research 的核心青年科学家,被视为“Masked Diffusion → Unified Multimodal Generation → World Model”进化路线上最具代表性的华人少壮派旗帜。他作为第一作者或核心主导者,先后推出了在开源社区引发轰动的 Meissonic 高效生成架构,以及实现多模态大一统的 Muddit 离散扩散基础 Backbone。白晋斌的研究打破了自回归模型与传统扩散模型的效率瓶颈,通过非自回归的掩码生成机制,极大地提升了多模态数据的并行处理与生成推演能力。他是将颜水成统一生成哲学转化为硬核代码与高效模型的关键核心推手。

冯佳时(Jiashi Feng)
冯佳时是计算机视觉、大规模多模态生成以及深度学习领域的资深专家与核心学者。他本科毕业于中国科学技术大学(USTC),随后在新加坡国立大学(NUS)获得博士学位,并曾于加州大学伯克利分校(UC Berkeley)从事博士后研究。在加入工业界前,他曾任新加坡国立大学助理教授,长期主持视觉学习与物体识别实验室,在 CVPR、ICCV、NeurIPS、ICML 等国际顶级人工智能会议和期刊上发表了数百篇高水平论文,在学术界具有广泛的影响力。
在迈入大模型时代后,冯佳时加入字节跳动担任 AI Lab 视觉负责人之一。他带领团队长期深耕于大规模视频大模型、跨模态时空理解以及三维视觉前沿的算法攻坚。在世界模型的技术演进中,他专注于攻克视频生成在时空连续性、多物交互一致性以及复杂物理规律模拟等方面的底层技术难题。通过将前沿的自监督表征算法、扩散模型架构与工业级算力进行高密度工程融合,他率领团队为字节跳动视觉大模型生态(如豆包、Volcano Engine 相关视觉底层技术)的跨越式升级,以及向可交互世界模型的升维,筑牢了关键的算法与工程底座。

林敏(Min Lin)
林敏是深度学习领域的资深学者与核心算法专家。他本科毕业于清华大学,随后在新加坡国立大学获得博士学位。在学术研究阶段,他作为第一作者发表了深度学习里程碑式的经典论文《Network In Network》(NIN),在业内首次引入了 1x1 卷积 架构与全局平均池化(Global Average Pooling)设计。这一颠覆性的结构随后被广泛采纳并融入到 ResNet、Inception 等几乎所有主流深度视觉网络中,成为现代大模型与世界模型构建底层地基时不可或缺的基础计算组件。
在步入工业界后,林敏加入字节跳动 AI Lab 并担任核心技术骨干,长期主持大规模多模态表征、视频深度理解与自监督学习的前沿算法攻坚。他专注于将早期的网络拓扑创新转化为支持万亿级数据训练的工程实体,在大规模生成式 Backbone 与时空动态因果律的交叉研究中贡献了重要突破,是国内从基础 Backbone 理论源头跨越到工业级视频大模型演进的关键少壮派学者。

第四派:范麟熙的物理仿真与具身控制派(The Physical AI & Embodied Control School)
这是世界模型的“物理行动派”。在这一流派的逻辑中,世界模型好坏的终极评价标准,绝不是生成的画面有多么逼真、多么符合艺术审美,而是这套模型能否真实还原物理规律,从而支持机器人(Robot Learning)和自动驾驶(Autonomous Driving)在虚拟的数字孪生世界中,以极低的安全风险和几乎为零的现实成本进行高强度学习、训练与闭环演练。
这一派的核心哲学强调 Physical AI(物理人工智能)、真实部署(Sim-to-Real)以及合成数据(Synthetic Data)的闭环生态。他们致力于打造一个拥有完美物理规律的“数智宇宙”。
产业界风头最劲的 NVIDIA Cosmos 系统,正是这一理念的标杆。它不是一个供人观赏的视频生成器,而是一个专门为机器人、自动驾驶和智能工厂打造的通用物理基础模型平台(World Foundation Model Platform)。在这一平台上,游戏渲染、虚拟仿真、机器人训练和具身智能体(Embodied Agents)被完美地粘合在一起。模型通过吞吐庞大的传感器数据,学习摩擦力、重力、流体力学以及碰撞体积,从而在虚拟世界中实时生成具备真实物理反馈的轨迹与交互环境,让 AI 智能体在虚拟世界里“练级”,出来后直接在现实世界中“无缝上岗”。
代表机构
•NVIDIA Cosmos / NVIDIA GEAR: 由英伟达主导的超级产业巨擘,不仅提供世界模型的底座算力,更定义了物理仿真世界模型的工业标准。
•UT Austin RPL / Stanford REAL / Columbia RoboPIL: 由顶级名校(德克萨斯大学奥斯汀分校、斯坦福大学、哥伦比亚大学)组成的学术铁三角,主攻机器人操作与物理仿真的最前沿。
•UCLA VAIL / OpenDriveLab & HKU: 加州大学洛杉矶分校以及香港大学等顶尖华人实验室网络,深耕于自动驾驶端到端闭环仿真、轨迹生成与开放世界感知。
代表人物
刘洺堉(Ming-Yu Liu)
作为英伟达(NVIDIA)AI 研究副总裁及 Cosmos 核心发起人之一,刘洺堉是全球计算机视觉、深度生成模型与物理仿真领域的泰斗级华人领袖。他先后主导了极其经典的 UNIT、MUNIT 以及风靡全球的 GauGAN 等里程碑式生成算法,直接奠定了英伟达在图像与视频生成领域的底层技术王座。在世界模型的争夺战中,刘洺堉带领英伟达团队重磅推出 Cosmos,将视觉生成完全推向了服务于物理 AI 的硬核仿真新范式。他在半导体巨头内部卓越的算法洞察力与组织力,使其成为这一流派无可争议的产业核心领袖。

范麟熙(Jim Fan)
英伟达(NVIDIA)GEAR 实验室(通用具身智能代理实验室)的领衔科学家、联合创始人。作为全球创投圈和学术界最具社交号召力与技术穿透力的青年意见领袖,Jim Fan 笃信“通过数字世界模拟来通往现实具身通用智能”的宏大叙事。从早期获得 NeurIPS 杰出论文奖的 MineDojo(将整个《我的世界》游戏重构成 Internet 级别的 AI 训练沙盒),到后来名震科技圈的 Voyager(首个利用大语言模型实现终身自主学习的游戏 Agent),他完美展现了将虚拟游戏、仿真平台与大模型融合的战略野心。在英伟达内部,他深度参与定义了“物理人工智能”的演进方向,致力于将视频生成、虚拟环境与物理 AI 完美粘合,是当前交互生成与具身智能学派里最活跃的产业布道者与核心操盘手。

朱玉可(Yuke Zhu)
德克萨斯大学奥斯汀分校(UT Austin)计算机科学系助理教授、机器人感知与学习(RPL)实验室主任,同时兼任英伟达 GEAR 实验室资深研究科学家。作为具身智能领域的硬核青年宗师,朱玉可的研究核心专注于机器人操纵(Robot Manipulation)、多模态感知以及仿真到现实(Sim-to-Real)的闭环迁移。他与 Jim Fan 紧密合作,共同主导了 VIMA、Voyager 等一系列具身智能里程碑工作的诞生。朱玉可的学术风格更偏向于硬核工程落地,他通过构建具备严密物理常识(如重力、流体力学、碰撞体积)的虚拟仿真环境,让 AI 智能体在其中进行高强度的“闭环演练”,进而解决机器人领域长期存在的高质量数据荒问题,是连接大模型决策与物理硬件控制的关键青年中枢。

宋舒然(Shuran Song)
斯坦福大学(Stanford)助理教授、REAL 实验室(机器人与具身智能实验室)负责人,曾任哥伦比亚大学 RoboPIL 实验室执掌者。作为全球“多模态具身感知”领域的顶尖华人青年科学家,宋舒然以极富灵性的机器人抓取、非刚性物体操纵以及三维视觉研究闻名。她极其擅长让机器人理解物理世界中的摩擦、拉伸与形变,在具身操控的工程落地和接口上展现了极强的创新力(如手持硬件接口 UMI 平台)。在世界模型与具身智能加速融合的浪潮中,她与团队展现出强大的跨界攻坚能力,联合推出了 Cosmos Policy 等前沿工作,通过微调视频大模型来直接进行视觉运动控制与规划,是学术界在“具身智能与世界模型派”中最具技术穿透力的青年领军人物。

李昀烛(Yunzhu Li)
哥伦比亚大学(Columbia University)计算机科学系助理教授。作为代表了学术界在“神经物理模拟”与“视触觉融合”领域最高水平的顶尖青年学者,李云珠深耕于粒子级物理大模型(Particle-based Physical Model)与多模态感知。他的研究致力于让 AI 能够像人类一样,不仅依靠视觉的“看”,更依靠触觉与力学的“感觉”来建立对周围物质力学属性的认知。通过将三维视觉、神经物理模拟与机器人控制深度结合,他的工作为世界模型注入了更加细腻、硬核的微观物理动力学常识,是物理行动派中深挖“智能体如何真正理解并改变物理世界”的关键学者。

周博磊(Bolei Zhou)
周博磊现任加州大学洛杉矶分校(UCLA)助理教授,曾任教于香港中文大学,是生成式人工智能与自动驾驶闭环系统领域的顶尖青年学者。他提出的场景理解、可解释 AI 算法在自动驾驶界被广泛应用。周博磊近年来的工作(如其团队主导的 VAIL 实验室相关项目)核心聚焦于“以世界模型重构自动驾驶仿真环境”,通过生成极其逼真且具备物理反事实推演能力的交通流场景,让自动驾驶系统在虚拟极端路况(Edge Cases)中进行安全的自适应学习,是连接大模型生成能力与大交通工业的硬核推手。

李弘扬(Hongyang Li)
作为上海人工智能实验室 OpenDriveLab(开放自动驾驶实验室)的领军人物、香港大学助理教授, 厉海洋在“大模型赋能自动驾驶”这条长坡厚雪的赛道上展现出了惊人的学术统治力. 他带领团队长期深耕于“驾驶世界模型”(Driving World Model)的前沿探索, 其核心主张在于:未来的自动驾驶不能再依赖死板的硬编码规则, 而是需要通过对海量道路视频及车辆轨迹数据的自监督学习, 训练出能够理解时空因果律的通用底座. 在步入大模型与生成式世界模型交融的时代后, 他进一步联合团队推出了 UniVLA 等具身大模型工作, 持续拔高自动驾驶与通用物理 AI 系统的决策上限, 是国内“自动驾驶与具身智能派”中极具战略视野的领军人物.

陈立(Li Chen)
上海人工智能实验室 OpenDriveLab 核心青年骨干及关键学者. 作为端到端自动驾驶领域的硬核少壮派代表, 陈立作为第一作者带领团队重磅推出了 UniAD(Unified Autonomous Driving)架构, 首次将全栈驾驶任务(感知、预测、规划)完美整合进单个神经网络中, 并凭借这一里程碑突破斩获了 CVPR 2023 的最佳论文奖. 他的研究不仅实现了解策范式的重大跨越, 更是通过数据驱动的方式, 让 AI 能够像人类老司机一样在“大脑”中实时预测周围车辆、行人在未来几秒内的空间运动意图. 他的这一谱系工作直接连接了生成大模型的能力与大交通工业的实战落地, 是世界模型在自动驾驶领域演进的技术风向标.

第五派:交互生成与游戏世界派
这是世界模型的“交互环境派”。它将世界模型的研究终点从单纯的“死视频生成器”推向了“神经游戏引擎”(Neural Game Engines)甚至“全知训练沙盒”。
这一派系认为,真正的世界模型不能只像一个放映机那样输出不可交互的固定画面,它必须是一个能实时对外界动作(Actions)做出物理和逻辑反馈的动力学系统。其关键技术在于通过从海量无标注的互联网视频(如玩家游戏录像、机器人操作视频)中自监督学习,无中生有地剥离出隐式动作接口(Latent Action Interface)。
在这种范式下,只需给模型输入一张静态的网页截图、手绘草图甚至是现实照片,AI 就能在神经网络的潜空间(Latent Space)里,瞬间实时生成一个可以由键盘、鼠标或 Agent 指令控制、会受伤、有碰撞体积、会产生物理反馈的“可玩世界”(Playable Worlds)。它彻底模糊了视频生成与实时电子游戏之间的边界。在当前更宏大的 AI 叙事中,它正成为下一代超级 AI Agent 在走向物理世界之前,进行千万级无限课程学习(Never-ending Curriculum)的高效虚拟练兵场。
代表机构与学术阵营
•Google DeepMind Genie 团队: 这一流派的开创者与学术主峰,先后推出了 Genie、Genie 2 和最新实现 720p 实时高一致性模拟的 Genie 3。
•NVIDIA GEAR 虚拟智能体分支: 英伟达旗下专攻多模态大模型、虚拟世界对齐与游戏智能体生态的工业巨擘线。
代表人物
史宇歌(Yuge “Jimmy” Shi)
史宇歌毕业于牛津大学并取得博士学位,现任 Google DeepMind 核心研究科学家,也是开创全球“神经游戏引擎”先河的里程碑工作 Genie(Generative Interactive Environments) 的共同核心作者。史宇歌的研究专注于生成式大模型的潜空间解耦与无监督动力学推演。她与团队打破了传统世界模型需要依赖游戏引擎标注动作(Action Labels)的限制,证明了 AI 可以通过纯粹“观看”互联网视频,自己悟出物理世界的操控逻辑(如跳跃、碰撞、场景卷轴移动)。她是把大模型从“单向视频生成”推向“双向动作可控交互”的最前沿核心华人推手。

张静惟(Jingwei Zhang)
张静惟同样是活跃在 Google DeepMind 基础大模型与世界模型研究前沿的核心华人科学家,深度参与了 Genie 这一基础世界模型(Foundation World Model)家族的架构设计与跨模态演进。在步入 2026 年后,张静惟与团队在 Genie 3 的迭代中扮演了重要角色,将这一流派的研究重点从最初的 2D 像素关卡彻底拓宽到了对流体、天气、复杂动画角色甚至物理生态环境(如水流雷电、植物生长)的高动态、高分辨率实时模拟。他的工作极大地拉近了虚拟神经环境与真实物理感知之间的距离。

王冠志(Guanzhi Wang)
王冠志是英伟达(NVIDIA)高级研究科学家,长期深耕于大规模强化学习、神经仿真环境以及通用具身智能体的决策架构。他与 Jim Fan 紧密合作,是 MineDojo、VIMA 以及英伟达大一统具身大模型 GR00T 基础系统(如最新的 GR00T N1.7)演进背后的硬核算法功臣。王冠志的研究重点在于打破虚拟与现实的隔离,他通过在高度复杂的虚拟可交互环境中训练大模型,让 AI 学习复杂的长程任务规划(Long-horizon Planning),再将这种在神经沙盒中获得的控制经验完美迁移至现实硬件,是连接交互环境与控制实战的关键中枢。

姜云凡(Yunfan Jiang)
姜云凡目前是斯坦福大学计算机科学博士生,师从李飞飞与吴佳俊,同时在英伟达 GEAR 实验室担任核心研究员。他是一位典型的横跨“物理仿真派”与“交互环境派”的少壮派跨界奇才。他作为核心作者主导了包括 VIMA、Voyager 以及最新面向全场景多任务家务机器人的大一统仿真平台BEHAVIOR Robot Suite (BRS) 的开发。姜云凡的工作极具灵性,他擅长直接将大模型注入到像《我的世界》或高度逼真的三维数字孪生场景中,通过构建会实时反馈的反事实交互环境,迫使 AI Agent 在玩游戏、做家务的互动中自我进化,是少壮派中将“游戏交互”与“机器人学习”融合得最好的代表人物之一。

杨云聪(Yuncong Yang)
杨云聪是活跃在计算机视觉与大规模生成式视频架构领域的硬核工业界专家,也是将国内大模型生态从“单向视频生成”推向“可交互神经世界模型”的强悍力量之一。他敏锐地捕捉到了生成式 AI 向可交互环境演进的技术趋势,并深耕于多模态空间动力学的前沿探索。通过主导或参与一系列虚拟环境生成项目与行为控制网络的研发,杨云聪致力于攻克大模型在长时间轴、多物体交互下画面逻辑崩溃的工程顽疾。他在底层算法与空间动力学上的深厚造诣,为开源社区和产业界在“交互式视频世界模型”的追赶与演进中,提供了坚实且高可扩展的技术底座。

王长虎(Changhu Wang)
王长虎是计算机视觉与视频生成大模型领域的学者与工业界专家。他本科与博士均毕业于中国科学技术大学(USTC),随后在新加坡国立大学(NUS)从事博士后研究,并曾任微软亚洲研究院(MSRA)主管研究员。在学术研究阶段,他主要专注于多媒体检索与计算机视觉前沿探索,在相关领域的国际会议和期刊上发表了百余篇论文,并拥有数十项专利。
在担任字节跳动视觉技术负责人之后,他于 2023 年创立了爱诗科技(AIsphere),并推出了 AI 视频生成平台 PixVerse。在技术路线上,他专注于推动视频生成从传统的单向文本/图像生成视频,向具备交互属性的视频世界模型演进。围绕大规模视频生成在复杂物理规律和长时序下的物理一致性难题,王长虎率领团队研发了多模态空间动力学网络,其相关技术在工业界逐步落地,为推动大模型生态从单一的内容生成工具向具备交互能力的神经游戏环境与仿真沙盒的发展,提供了相应的工程与算法支撑。

朱灏怡(Haoyi Zhu)
朱灏怡是计算机视觉、多模态时空理解与视频大模型领域的青年学者。他本科毕业于北京大学,随后在中国科学院大学(UCAS)获得博士学位,并曾在上海人工智能实验室(Shanghai AI Lab)担任高级研究员。在科研阶段,他专注于人体动作捕捉、大规模视频时空表征学习以及自监督表征算法的研究,在 CVPR、ICCV、ECCV 等计算机视觉顶级会议上发表了多篇高水平论文。
五大学派的分歧:他们到底在争什么?
世界模型被公认为大模型之后的"下一战",但在这场技术长征的底层,五大学派正在进行的不是细枝末节的修补,而是一场关于"智能如何形成"的范式战争。
要不要生成像素,是最根本的路线之争。
Yann LeCun 代表的隐式表征派认为,执着于重构每一个像素是愚蠢的。现实世界里随风摇晃的树叶、水面的波纹、电视机的雪花点,这些无意义的背景噪声对智能体的决策毫无帮助。世界模型应该直接在隐空间(Latent Space)中进行联合表征,只预测与任务、行动和语义相关的核心特征,绝不把算力浪费在"画出逼真画面"上。
但李飞飞的 3D 世界派和颜水成的统一多模态生成派走向了相反的方向。在他们看来,像素和高保真的 3D 几何结构是检验模型是否真正理解现实的唯一硬性指标。如果不把空间以 3D 形式显式重构出来,AI 就无法真正理解物体的体积、遮挡和深度;而能够生成高质量、多模态、高保真的视觉像素,恰恰说明模型内部已经蕴含了物理世界的常识。
这种分歧直接决定了世界模型"为谁而生"。
NVIDIA Cosmos、宋舒然、厉海洋代表的物理仿真与控制派,将世界模型视为具身智能的"安全练兵场"和"大脑规划器"。它的存在是为了让机器人、自动驾驶系统在没有真机风险的情况下,学习摩擦力、碰撞、路径规划和视觉运动控制。画面再逼真,如果重力参数或力学反馈不对,导致真机部署失败,这个世界模型就是零分。
而 DeepMind Genie、Jim Fan 代表的交互生成与游戏世界派,则把目光投向了人类玩家、游戏开发者和数字空间里的 AI Agent。他们的目标是无中生有地创造一个可玩、可操作的虚拟神经游戏世界,更偏向娱乐、内容创作生态,以及作为纯虚拟智能体实现终身学习的"数字沙盒"。
服务对象不同,度量衡便完全无法对齐。
物理仿真派只认 Sim-to-Real 的闭环成功率:在虚拟世界里训练出来的自动驾驶系统或机械臂,部署到真实的马路和工厂里,能不能安全上路?能不能精准抓取?李飞飞的 3D 世界派更看重空间几何与视角的一致性——当你任意移动相机、切换视角时,物体会不会穿模?光影变化是否符合物理规律?颜水成的统一生成派则用典型的 AIGC 指标衡量:处理千万级超大规模跨模态数据时,推理并行效率是否足够高?生成的图像和视频是否逼真、没有伪影?
五派之争的本质,是人们对"理解世界"这件事的不同定义。 有人追求像素级的真实,有人追求语义级的效率;有人服务于钢铁与马达,有人服务于屏幕与想象。而世界模型最终会长成什么模样,或许取决于谁先把自己的度量衡,变成整个行业的度量衡。
新范式浮现:物理规则原生派与统一世界模型
但 2026 年的硅谷,一个超越五派分歧的底层共识正在悄然汇聚。
这一年春天,三件事在三个时区同时发生:Jim Fan 在 NVIDIA GEAR 调试 Cosmos,试图让重力参数不再依赖外挂引擎;DeepMind 的 Genie 3 跑通了流体模拟,检验模型对陌生动作的物理反馈;颜水成与白晋斌的 Muddit 模型,正用同一套离散扩散框架同时处理视频、机器人动作和文本。
三件事指向同一个判断:世界模型不应再被定义为"生成器"或"仿真器",而应被重新定义为"物理状态的维护者"。
这不是第六派,而是三条独立脉络在同一个技术判断上的自然汇聚。
•脉络 A(统一多模态):颜水成/白晋斌的 Meissonic 与 Muddit 证明,当图像、视频、动作、文本被离散化为 Token,它们在数学结构上可以完全一致。多模态不是独立数据类型,而是共享同一套语法。冯佳时、林敏等人为这条路线筑牢了工程底座。
•脉络 B(物理仿真):Jim Fan/刘洺堉的 Cosmos 不再被训练来"生成好看的视频",而是被训练来"维持物理一致性"。宋舒然、朱玉可、李昀烛等人的工作共同指向:物理规律不应是外挂过滤器,而应成为训练约束。
•脉络 C(交互生成):Demis Hassabis 的 Genie 路线提供了一个关键试金石:世界模型真正的考验,不是生成视频,而是对从未见过的动作产生合理的物理反馈。史宇歌、张静惟、姜云凡等人证明,模型必须"拥有"一个世界,而非仅仅"记得"一些画面。
这三条脉络的共同锚点,是"统一世界模型"(Unified World Model)。 它不属于任何单一学派,而是上述三条路线在同一个技术判断上的自然汇聚。
统一世界模型的底层逻辑,借用了物理学中的统一场论:引力、电磁力、强弱核力只是同一底层场的不同表现。同理,文本、图像、视频、动作——这些被 AI 行业长期割裂处理的"数据类型"——只是同一个世界状态在不同维度上的投影。
一块石头滚落:在视频中是像素光流,在音频中是碰撞频谱,在动作中是重力轨迹,在文本中是六个字。传统 AI 为每种模态训练专门的编码器,再用对齐层"翻译"成同一种语言。统一世界模型则反其道而行:从多个不完整的投影出发,反推出那个唯一的统一世界。
技术上,这依赖三个相互咬合的齿轮。
•离散扩散统一:将多模态数据拉到同一数学空间,完成原生统一。白晋斌的 Muddit 证明了这种统一在工程上可行——不是概念上的,而是代码层面的。
•掩码建模因果:遮住视频后半段、删掉动作序列、遮蔽关键词,强制模型回答"缺失的世界状态是什么"。这不是学习像素相关性,而是学习世界状态之间的因果约束。
•物理约束嵌入:传统模型把物理规律当作可选项,生成完再用引擎检查。统一世界模型将其作为硬约束直接写进目标函数。空间结构、运动规律、因果时序不是后验修正,而是先验条件。
统一世界模型要求一种前所未有的能力:当面对物理上不可能的输入时,模型必须产生可识别的偏差信号。模型不仅要推演世界,还要在推演出错时自己知道错了。它不依赖人眼判断"真不真",而是用一个可量化信号回答:我当前维护的世界状态,在物理上是否自洽?
这是目前唯一将"自我验证"作为第一性原理的路线。LeCun 的 JEPA 无法自我验证物理一致性;李飞飞的 3D 重建能检查几何,但检查不了因果;Jim Fan 的 Cosmos 可以仿真,但仿真的是预设引擎的物理,而非模型内生的理解。
华人学者网络:世界模型背后的新一代 AI 版图
如果说过去几年的大语言模型主线,长期由OpenAI、Google、Anthropic等硅谷巨头牢牢定义,那么在"世界模型"这一更强调多模态、三维空间、物理规律与具身交互的新战场上,权力版图明显变得更为分散,也更值得注意——在几乎每一条关键路线上,华人学者都早已不再是旁观者,而是无可争议的核心建构者。
从李飞飞、吴佳俊、王建元所引领的"3D世界派",到颜水成、白晋斌坐镇的"统一多模态生成派";从刘洺堉、宋舒然、李弘扬领衔的"物理仿真与具身控制派",再到史宇歌、张静惟、范麟熙活跃的"交互生成与游戏世界派",华人学者的身影纵横交错。他们横跨了从硅谷巨头、高校顶级实验室到前沿开源社区的每一个核心生态位。
这种"撑起半壁江山"的群体性崛起,背后交织着双重红利:
第一,学术沉淀的代际接力。华人学者在计算机视觉、三维重建以及机器人控制领域拥有长达数代际的学术积累。当大模型从"纯文本的符号世界"走向"物理的像素世界"时,这些原本就深谙几何、光影与力学的科学家们,自然而然地接过了历史的接力棒。
第二,庞大而高频流动的知识网络。这不仅是单个天才的闪光,更是一个师徒传承、同窗合作、产学双栖的生态系统。李飞飞与吴佳俊、姜云凡的师承脉络,各大顶尖高校华人PhD群体的高密度协作,以及刘洺堉在英伟达产业端与学术界的联合研发,使得最新、最硬核的算法能以极快速度在不同流派间碰撞、验证并开源落地。
世界模型的下一战,本质上是AI重新编码现实空间、吞噬物理世界生产力的战争。在这场关乎下一代通用人工智能主权的巅峰对决中,这一张由华人学者交织而成的全新AI版图,不仅在为全球科技注入源源不断的范式创新,也注定将成为决定未来产业格局走向的最关键变量。
(来源:Z Finance)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



