

让AI像人一样操作手机,是过去一年最火的赛道之一。
填表单、回消息、预订车票,甚至帮你刷小红书——Mobile GUI Agent(手机图形界面智能体)的目标,就是只看屏幕截图,就能像真人一样把手机玩明白。
可一个尴尬的现实是:这帮Agent在日常手机环境里到底有多强、要怎么练得更强,几乎没人能可靠地说清楚。
问题不在模型,在它们脚下的那片「地」——既没有靠谱的考场,也没有便宜的训练场。
想训练、评测手机Agent
怎么就这么难?
要训练、评测手机Agent,你总得有个能跑微信、支付宝的环境。可现实是,能跑真实日常App的,只有模拟器和真机两条路,而且条条都是坑。
第一条路,安卓模拟器。
它其实装得上微信、支付宝——但App的风控一眼就认出模拟器这种「非常规环境」,轻则闪退、运行不稳,重则直接封号。根本没法稳定地拿来做评测。所以这类环境往往只能退守计算器、设置这类系统工具和开源App,最高频的国民级App反而碰不得。
更何况它还「重」:一个实例动辄吃掉 4.5GB 以上内存,想大规模并行训练?那就是赤裸裸地烧钱。
第二条路,真机。
真手机够稳、够真。可代价是——想并行就得买上百台手机、养一堆真实账号,真金白银地砸;而且一台手机一次只能跑一个任务,吞吐低到感人。
更要命的是,真机连「并行 rollout」都做不到。 像GRPO这类常用 RL 算法,要求从同一个初始状态并行拉出一整组轨迹来对比好坏,可你手上就一个微信号,克隆不出 N 份内容、好友、余额完全一样的副本——「从同一状态分身出几十条轨迹」这种训练刚需,真机上根本无从谈起。
而最致命的死结,两条路都躲不掉:只要登的是真实账号,操作就是玩真的。
真转账就是真扣钱,真购票就是真下单。更麻烦的是跑完之后想复位——
哪怕只是改了个设置、点错个关注,想还原,也得靠人工、或让Agent反向操作一步一步抠回去,繁琐又容易出错;
转账、注销这种彻底不可逆的操作,反向操作都救不回来。
一个任务测一遍,环境就「脏」了。可复现、可批量的训练和评测,从根上就立不住。
对于评测也只能退而求其次——让另一个大模型看截图来当裁判。可这种「VLM当judge」主观、易误判、还难以审计。后面会看到,它的误判率高达 10.2%。
说到底,这一切的根源只有一个:日常App的内部状态,天生就读不到、没法改、也复制不了。
换个脑回路:Agent只看截图
那我只在「像不像」上较真
中科院团队的破局思路,堪称「四两拨千斤」。
既然真实 App 的状态读不到、改不回、也复制不了——那干脆别在真机上死磕了:索性自己在浏览器里造一个仿真的安卓世界。在这个世界里,所有状态都由我们说了算,想读就读、想改就改、想复制就复制,前面那三道坎瞬间清零。
唯一的疑问是:这么「造」出来的东西,Agent 会不会一眼就看穿「是假的」?
答案,藏在一个最朴素的事实里——GUI Agent 的眼里只有截图,手里只有点击。
那又何必去复刻像素级的安卓内核、复刻真实App背后的服务器后端?
只要点下去,界面给出对的反应、该变的状态真的变了,对Agent来说,这个世界就足够「真」了。
这就是论文中强调的核心——交互保真(interaction fidelity)。
于是 MobileGym 诞生了:一个完全跑在浏览器里的、轻量级安卓仿真环境。
团队硬是在浏览器里实现了一整套安卓运行时机制:任务栈、键盘、通知、权限流、intent路由、返回键派发……它覆盖了28个App(12个日常App + 16个系统App),微信、小红书、支付宝、B站、 谷歌地图、12306、腾讯会议、微信读书、Spotify、Reddit、X、eBay全都在内,连主题切换、动态桌面小组件都做了。
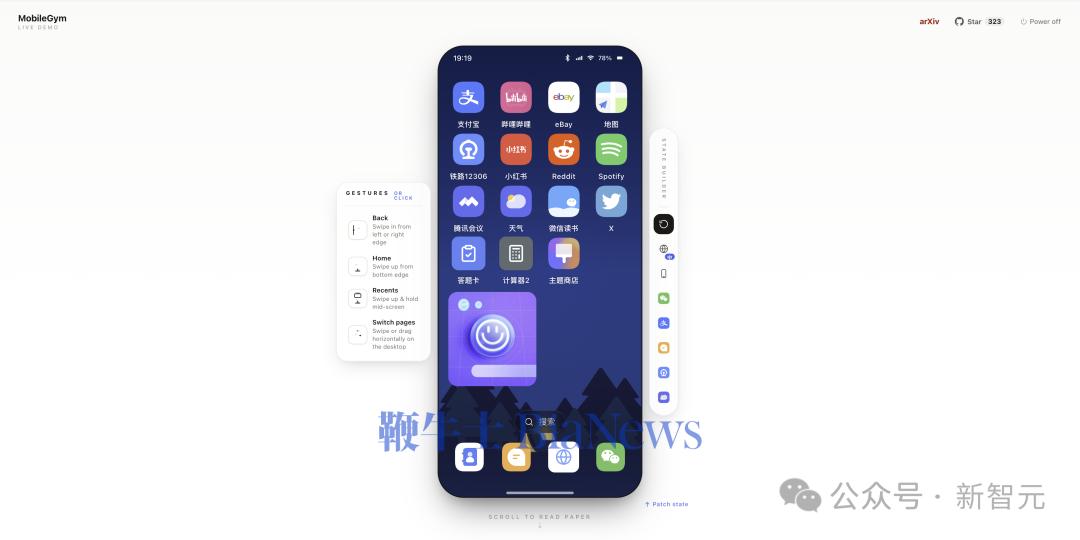
▲ 28 个 App 全是独立仿真,日常主要 APP 类别几乎全部涵盖。
仿真到什么程度?直接上图感受一下——
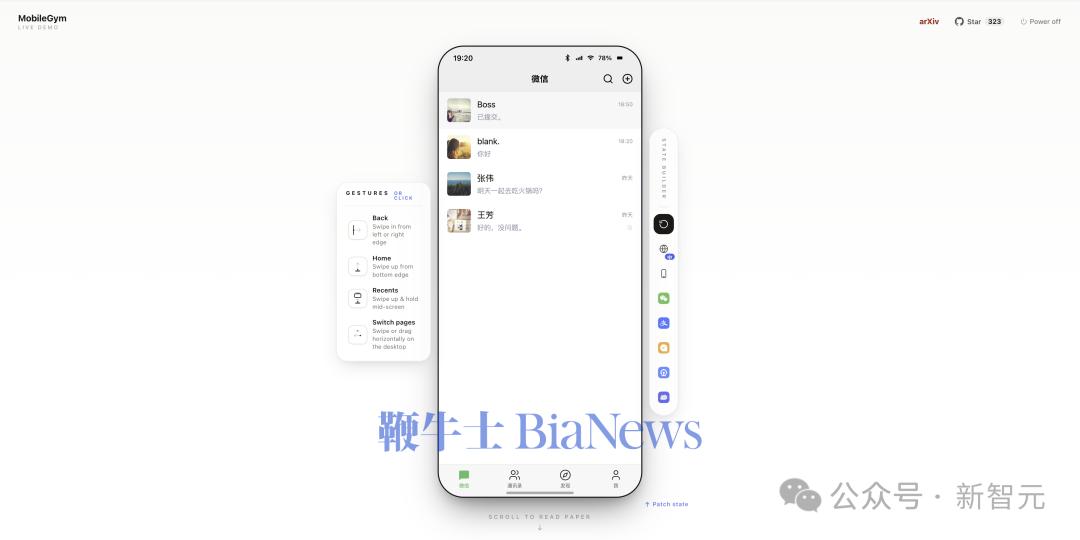
▲ 微信:聊天列表、对话、底部 Tab 一比一还原。
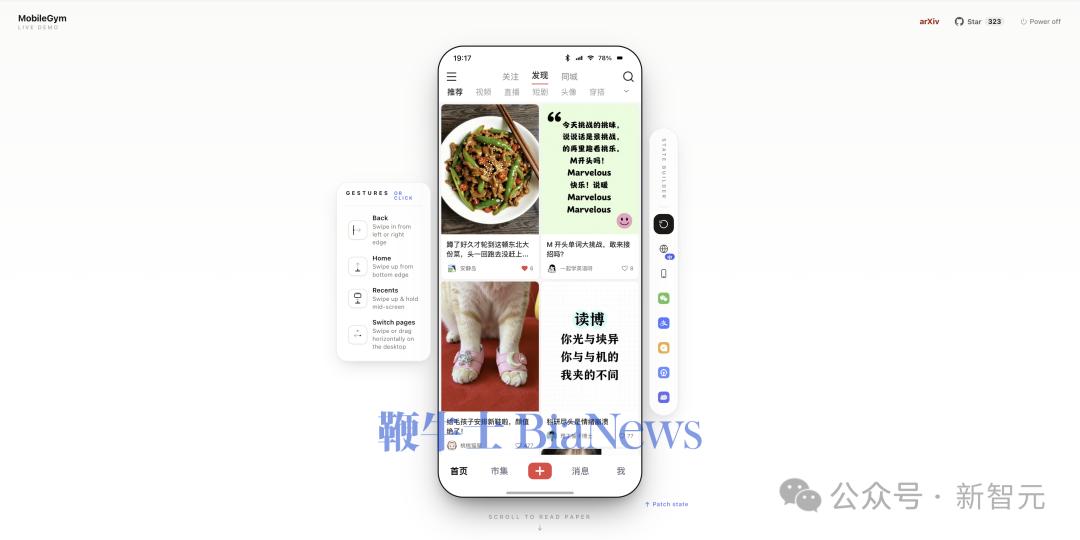
▲ 小红书:双列瀑布流、点赞、底部导航,刷起来毫无违和感。
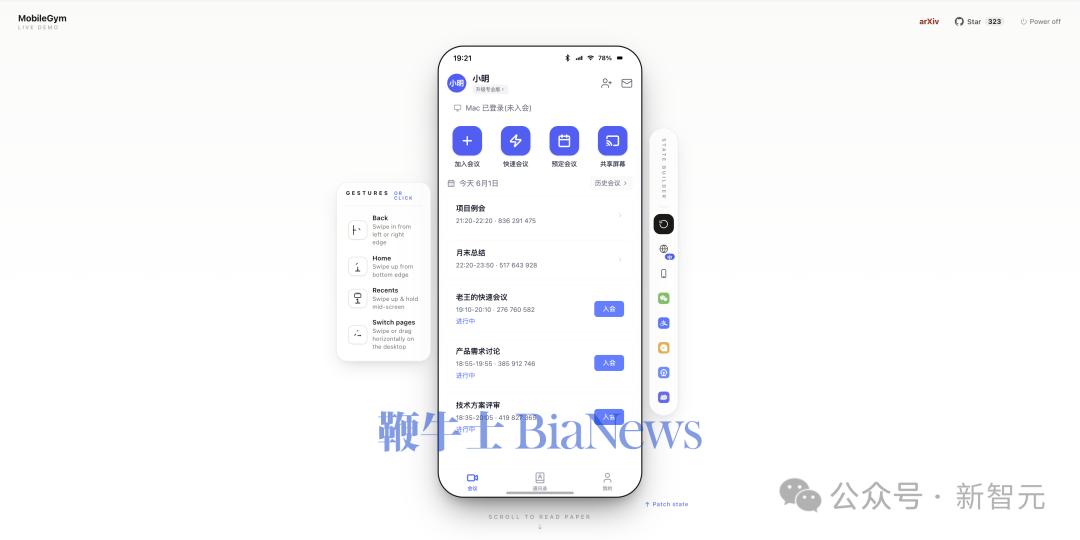
▲ 腾讯会议:加入/预定会议、会议列表,办公场景也照样覆盖。
顺带还有个有意思的细节:这个仿真出来的浏览器是 「真」能联网的——B 站评论区就有网友自己试了一把,挂上云原神直接在里面玩了起来,当场「原神,启动!」

▲ B 站网友实测截图:仿真浏览器里「原神,启动」。
玩出花的还不止一个,干脆有人在 MobileGym 里又打开了 mobilegym.dev——于是 MobileGym 里套了个 MobileGym,手机里开手机,一层接一层,活生生玩成了「俄罗斯套娃」。
▲ 套娃现场:MobileGym 的浏览器里又开了一个 MobileGym,手机里还有手机。
但真正的杀招,还藏在这套机制的底层。
一份JSON,把「读不到、改不回、复制不了」一次解决
MobileGym把整个环境的状态——App数据、系统设置、设备信息——全部用一份结构化JSON来表示。
正因为状态天生就是结构化的,前面那三个老大难,瞬间被逐一破解:
可读:程序直接读状态做确定性校验——余额、订单、设置项一览无余,彻底告别VLM看截图瞎猜;
可写:任意配置、一键重置到任何指定的初始状态;
可复制:毫秒级快照,从同一状态复制跑多条轨迹—— 真机克隆不出的"同状态分身",这里一份状态拷贝就搞定, GRPO 要多少条给多少条。
零后果:改设置也好、转账注销也罢,跑完直接拿初始快照整个覆盖回去——不靠反向操作一步步抠,毫秒级满血复活,绝无真实代价。
一鱼两吃:同一套信号,既当考官,又当教练
到这里,MobileGym最妙的设计才真正浮出水面。
既然环境状态可读、可被程序精确判定,那这份「判定」就有了双重身份:
对评测而言,它是一张确定的成绩单——任务到底完没完成,程序说了算,不用大模型猜;
对训练而言,它就是一个现成的奖励信号(reward)——Agent做对了多少,直接拿来喂给强化学习。
换句话说,同一套可验证信号,既是评测的成绩单,又是训练的奖励——一套环境,考、练通吃。
其实「可验证环境的考练一体」本身并不稀奇:AndroidWorld、MobileWorld这些前辈,靠程序化验证同样能既评测又训练。真正的难关在于——它们只够得着文件管理、设置这类系统工具和简单开源 App,一旦面对微信、支付宝,这套一体化能力就彻底卡死。MobileGym 的突破,是用「仿真 + 结构化状态」,第一次把这套可验证的「考练一体」,延伸到了真正高频的日常 App 上。
而这还只是一半。另一半是「快」和「省」——
因为整个环境就是一份结构化JSON,复制一份状态 = 克隆一个完整环境。一个实例只占约400MB内存、3秒冷启动,一台服务器就能同时开几百个并行环境。训练要的海量rollout、评测要的批量跑分,统统不用再堆服务器。而且,每条轨迹的判定都是程序读状态、毫秒级出结果,连一遍遍调用又慢又贵的大模型当裁判都省了。
论文还算了一笔账:如果改用 VLM 当裁判,一次 256 题评测,GPT-5.4 约要 158 元;放到 96 万条轨迹量级的 RL 训练,光裁判 API 就可能烧到约 60 万元。而 MobileGym 的程序化判定,这部分成本是 0。
把「可验证的考练一体」搬上日常 App,再叠加轻到能单机大规模并行——这套组合,过去几年模拟器和真机两条路谁都没能凑齐。 它顺带成就的,是让微信、支付宝这类日常 App,第一次能被确定、可复现地打分。
下面,我们就分别看看,它当「考场」和「训练场」,到底有多猛。
先看考场:9个顶尖Agent同台,最强也才考了58.8分
团队配套放出的 MobileGym-Bench,堪称「史上最严手机Agent考场」。它有多硬?
416个参数化任务模板(256测试 + 160训练),横跨28个App;
每道题都不是死的,通过参数化实例化能衍生出 超过27000个不同实例,从根上防止模型「背答案」;
4个难度等级L1-L4,不是拍脑袋定的,而是用8个参考模型实测校准出来的;
就连「问答题怎么判分」都被重做了一遍。 传统评测靠字符串模糊匹配,经常闹笑话——意思对了却判错,或者Agent在思考里碰巧带出正确答案就被误判成功。MobileGym干脆让Agent在界面上填一张结构化的 「答题卡」,系统按字段类型(精确文本、数值、格式、选项)逐项核对,堵死了这种漏洞。而且这招还顺手治了 GUI 专用模型的一个老毛病——它们生来就是被训练去「点界面」的,你非让它按固定文本格式把答案规规矩矩吐出来,它常常不买账、格式乱套;而答题卡把「答题」变成了「填表单」,这恰恰是它的看家本行,于是反倒老老实实照做了。
然后,9个知名Agent模型被拉来同台竞技,结果集体被按在地上摩擦:
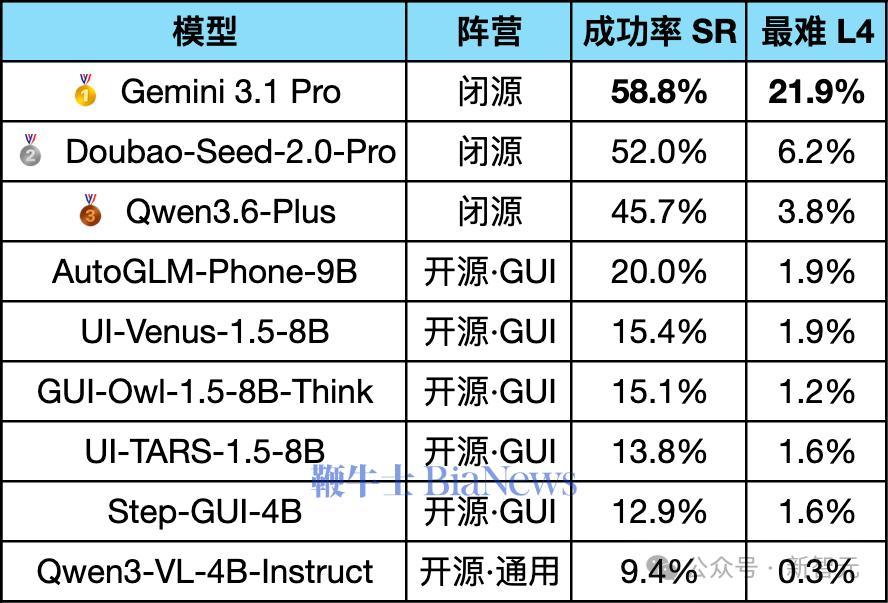
在最难的L4任务上,9个模型集体扑街,只有Gemini勉强保住21.9%。
这恰恰说明:这套考题区分度极强,既没被刷爆、也没难到全军覆没——是一把能真正照出手机Agent成色的好尺子。而得益于浏览器仿真的「轻」,256个并行实例,跑完整套256任务的评测,实测只要6分钟。
再看训练:一台机器顶一个机房,练完就能上真机
说MobileGym是「训练场」,绝非自封。
先说「省」到什么程度:此前有方案为了凑齐512个安卓模拟器实例做在线RL,动用了10台裸金属服务器、960个vCPU、3840GB内存。而在MobileGym上,团队用GRPO算法微调Qwen3-VL-4B 模型,一台服务器轻松开 96 个环境实例,并行跑 256 个环境实例也仅仅只需要 100G 内存。别人一个机房,这里一台机器。
再说效果:训练后,模型在测试集上的成功率从9.4%涨到22.2%(+12.8个百分点),实打实的提升。
但真正的考验是:模拟器里练出来的本事,搬到真手机上还管用吗?
团队把训练前后的模型,都搬到一台真实的红米手机上实测。
结果令人振奋:真机信号任务上,成功率从32.2%提升到72.9%(+40.7个百分点),95.1%的模拟训练增益,成功迁移到了真机!
在模拟世界里练的功夫,真机真能用。
还记得前面说的那个 10.2% 误判率吗?它正是从这组真机轨迹里、一条条人工复核抠出来的:118 条轨迹,让 Qwen3.6-Plus 当裁判,判错了 12 条。换个更强的模型行不行?团队真把 GPT-5.4 请来重判一遍——误判率还是 10.2%,只不过这回判错的换成了另一批任务。说白了,问题不在哪个模型不够强,而在「让大模型看截图当裁判」这条路本身就靠不住; MobileGym 用程序化状态校验,从源头就杜绝了这种误判。
USE指标:第一次抓出Agent「顺手作恶」
更妙的是,掌握了完整状态后,MobileGym还顺手解锁了一个别家给不了的「独家武器」——USE(意外副作用)指标。
设想一个场景:你让Agent帮你发条消息,它确实发了,任务「成功」了。但它有没有在你不知道的情况下,顺手错点了关注、错改了设置、甚至错发了另一条消息?
只靠大模型来看截图,很难发现得了。
而MobileGym能把任务前后的全环境状态做精确对比,任何任务之外的改动都无所遁形。实测发现,即便是成功率相近的开源模型,「作恶」概率也能相差近2倍。
这一点的价值远超评测本身。论文还专门测试了转账、注销、大批删除等高风险操作,发现前沿模型(Gemini 3.1 Pro)一旦被指令驱动,几乎「无脑」高成功率执行,毫无安全刹车。
也正因如此,这套「零后果 + 一键重置」的沙箱,天然成了AI安全对齐研究的理想试验田——让Agent在绝对安全的环境里,把危险动作先「演」一遍。
不是又一个Benchmark
而是一整套基础设施
回过头看,MobileGym真正的野心,从来就不是「再做一个更大的手机榜单」。
它把日常 App 的训练与评测——这件过去昂贵又难复现的事——收进了同一个可验证、可大规模并行的仿真世界:同一套状态,既是评测的成绩单,也是强化学习的奖励;同一台机器,既是几百场考试的考场,也是海量 rollout 的训练场。
当整个行业还在为「怎么可靠地训练和评测手机Agent」头疼时,这支国产团队,已经悄悄把那块最难啃的地基,稳稳地铺好了。
(来源:新智元)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



