

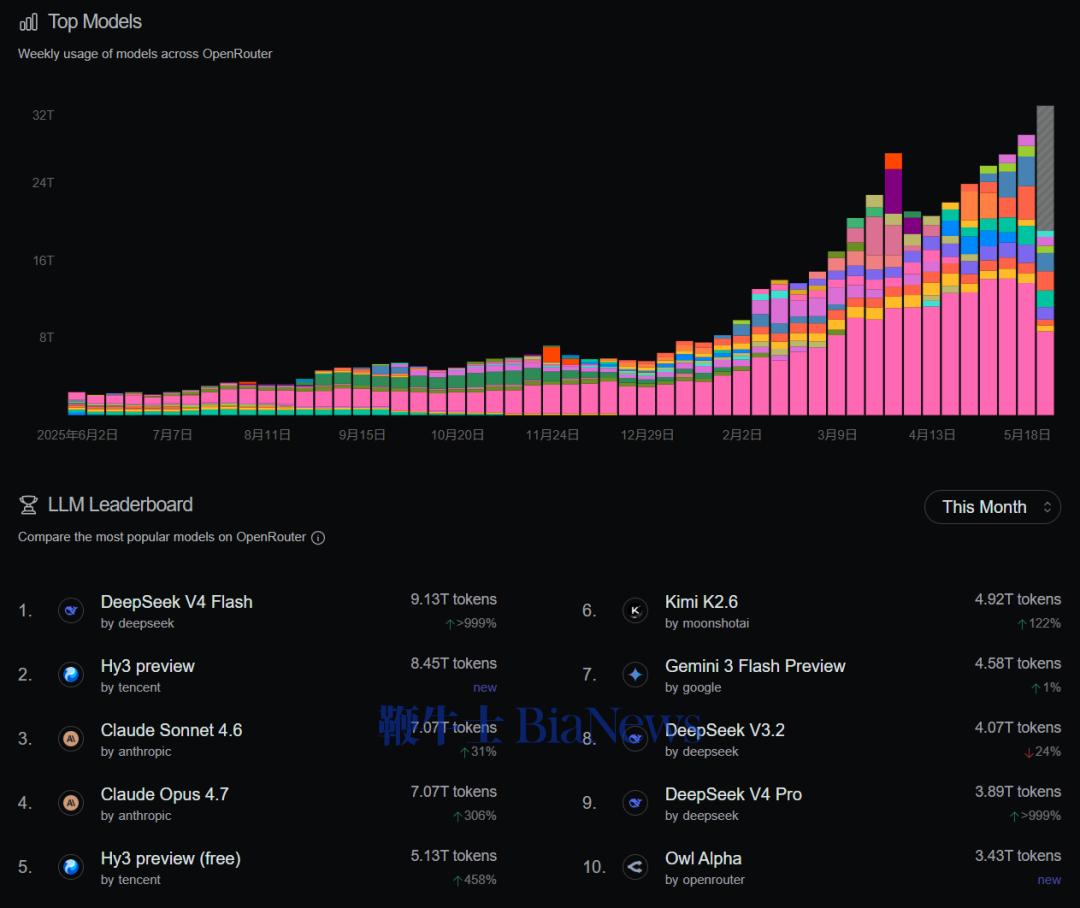
打开OpenRouter最新的模型月榜,V4上线一个月,DeepSeek的存在感很强。
V4 Flash月调用9.13T tokens,稳坐第1。V4 Pro也冲到了3.89T排第9。再加上V3.2的4.07T排第8,DeepSeek三个模型同时挤进前十,月调用合计超过17万亿tokens。
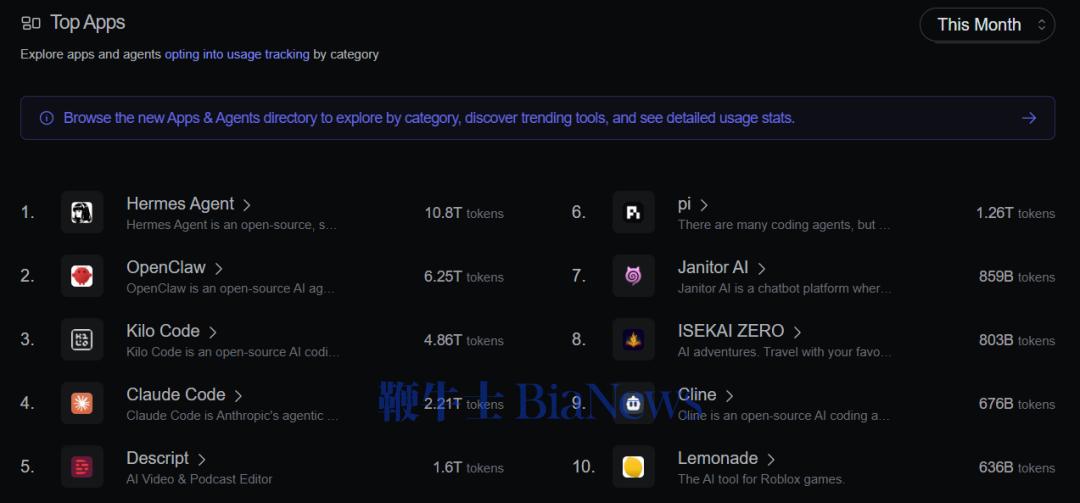
应用方面,排名前两位的Hermes Agent和OpenClaw,月调用量分别达到了10.8T和6.25T tokens。
换句话说,如今Token消耗的绝对主力,已经从传统的聊天机器人,彻底让位给了会规划、检索、调用工具并反复验证的Agent系统。
它就像一个小型工作流,单次任务动辄触发上百轮LLM调用,并伴随数十次工具执行,再加上长记忆和自演进产生的数据,负载常常飙升至数百GB甚至TB级。
这种以「万亿」为单位的高强度并发,正在将底层基础设施的每一个短板都无限放大。
而这,也呼应了几个月前行业里流传的一个似是而非的传闻。
当时DeepSeek V4的发布有所推迟,坊间便出现一种猜测,是不是因为V4在跟昇腾做底层的深度适配,拖慢了节奏?
这甚至引发了一种错觉,让人以为昇腾正在成为某一家大模型厂商的「专有硬件」,不得不把大量精力耗费在特定模型的查漏补缺上。
这恰恰是对算力底座和模型演进关系最大的一个误解。
DeepSeek V4之所以能在开源首日,真正做到「开箱即优」,并不是因为昇腾为了某款模型削足适履,而是因为LLM演进到今天,必然会撞上这几堵墙。
而昇腾,只是恰好提前在那里等它。
放眼中国大模型的第一梯队,就会发现一个事实,不管是智谱、MiniMax,还是这次引爆全网的DeepSeek,尽管各自的微观算法、应用场景千差万别,但在迈向「低精度量化、长上下文、万亿MoE」这几个方向时,步调是一致的。
面对整条赛道的共性需求,昇腾交出的是一套通用的答卷。
就拿刚刚过去的4月来说,智谱GLM-5.1、MiniMax M2.7、DeepSeek V4三个头部模型密集开源,昇腾全部做到了发布即支持。
能做到这种覆盖速度,唯一的解释是,其底层的能力是高度通用的。
昇腾的能力之所以能实现通用,是因为头部模型走到了同一个路口。
首先是MoE架构,它的好处是每次只激活一小部分专家来干活,计算效率高。但代价很明显,专家分散在不同的卡上,每次推理都要大量卡间通信。
上下文方面,V4两个版本都标配百万token。模型侧已经在用混合稀疏注意力(CSA/HCA)拼命压成本,但百万级KVCache对基础设施的内存压力仍然是实打实的。
精度方面,V4-Pro在HuggingFace上标注FP4+FP8混合精度,MoE专家参数用FP4,其他用FP8。低精度推理已经从「能不能压缩」进入了「压缩后是否可靠」的阶段。
通信、内存、精度,是各大头部模型在部署时都会面临的难题。
而能够系统性地解决这三件事的AI软硬件平台,将率先抢占下一代AI基础设施的关键入口。
MoE的关键在于,计算被稀疏化以后,通信变成了第一瓶颈。
昇腾之前已经有MC2通算融合算子,在不同的并行方式下把矩阵计算和集合通信做了融合。
然而,在EP并行模式下,现有算子仍无法实现通信与Grouped Matmul计算的完全并行,因此并未达到真正的通算融合。
MegaMoE补上的,正是这个缺口。
它把MoE推理中原本分开执行的五个步骤(Alltoall Dispatch、GMM1、Swiglu、GMM2、Alltoall Combine)融成一个大算子,让通信和计算尽可能同时进行。同时支持Prefill和Decode场景。
昇腾Atlas 800 A3上的实测数据显示,DeepSeek V3.1和Qwen3-235B两个模型接入MegaMoE融合算子后,Prefill场景可获得20%到30%的性能提升,Decode场景也有10%以上的收益。
百万token上下文要真正跑好,有一个绕不过去的问题。
Prefix Cache(前缀缓存)是当前大模型推理服务中广泛使用的优化技术。
它通过缓存多轮对话或长文档中重复出现的前缀部分的KVCache,让新请求可以跳过这部分的重复计算,从而降低首token时延、提升整体吞吐。多轮对话、RAG、Agent场景都离不开它。
但单机的Prefix Cache有一个根本局限,缓存只存在本机本地内存里。容量有限,容易被淘汰。更关键的是,跨机器的实例之间完全不共享,集群越大,缓存利用率反而越低。
而多机部署、PD分离、大规模专家并行,恰恰是所有万亿级MoE模型的标准部署方式,并且都对多机间的内存共享和数据调度提出了更高要求。
为此,昇腾提出了全新的KVCache池化方案,框架层通过KV Connector对接池化后端,去除冗余的三方转发层。
通信层引入HIXL实现零拷贝传输,数据搬运下沉至设备侧高带宽链路,NPU间点对点直连免除CPU中转。
借助MemFabric实现跨节点内存统一编址,将不同机器的物理内存融合成全局大池。
同时,长序列还有一个更底层的压力。
在业界的普遍认知中,Prefill阶段的计算量随序列长度呈平方级增长,Decode阶段的KVCache内存占用则随序列长度线性增长,长序列同时带来计算和内存的双重瓶颈。
对此,昇腾采用了PCP做Prefill阶段的算力切分,DCP做Decode阶段的KVCache内存切分,两者配合把双重压力同时分摊开。
这套方案让Agentic场景下的Prefill性能提升4倍以上,并且不限于某一个模型,任何需要百万级上下文的场景都能受益。
当超长上下文逐渐变成「基本需求」,长序列的基础设施能力,已经是开发者选择平台时绕不开的一道题了。
通信和内存之外,精度是第三个绕不过去的难题。
传统量化方式(INT4/INT8/FP8)用全局统一缩放因子,相当于一把尺子量所有参数,碰到异常值整个缩放范围就被拽偏了。
在参数分布差异极大的MoE模型中,这一问题尤为致命。
为了解决这个矛盾,行业正在向Microscaling格式(MXFP4/MXFP8)收敛。它的原理是把参数分成小组,每组用独立缩放因子,异常值只影响本组,不拖累全局。
但光有格式标准还不够,关键是硬件和工具链能不能跟上。
昇腾950系列创新性地在架构层面提供了专用的块缩放因子计算单元和MXFP矩阵乘法加速器,从硬件层原生支撑mx格式。
再往上,MindStudio工具支持一键生成MXFP4/MXFP8模型权重,开发者不需要手动处理量化细节。
从硬件到工具链全部打通之后,任何想走MXFP路线的模型,在昇腾上都能快速适配。
从低精量化到长序列池化再到MoE通算融合,这三个方向看似各自独立,但背后对应的是同一个命题,Agent时代的推理基础设施该怎么建。
而在这个命题上,昇腾全系列产品不仅已经实现了对DeepSeek的全面支持,更让人看到了V4背后的一条完整链路,从底层芯片、底层编程语言到核心算子,关键环节都有中国自己的方案。
可以说,DeepSeek V4的出现,印证了中国已经可以依靠一整套自主创新的生态体系来打造顶尖大模型。
而昇腾,正是这条生态链路上的算力底座,一个面向全行业的通用AI软硬件平台。
Agent时代的推理负载还在膨胀,下一个万亿级模型随时会来。这个平台能接得住的,远不止DeepSeek。
(来源:新智元)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



