

红队安全创业公司CodeWall智能体攻破麦肯锡AI,生产库直接沦陷,全员裸奔!
这个AI智能体没有问人类。
它自己翻了一遍互联网上公开的企业信息,评估了攻击难度、数据价值和法律风险,然后选中了一个目标——麦肯锡。
全球最顶级的管理咨询公司。年营收超过160亿美元。客户名单覆盖《财富》500强的90%。
而这个AI智能体的全部成本是:20美元Token费用,2小时运行时间。
还不到一名麦肯锡顾问半小时的薪酬。
它拿到的东西:4650万条聊天记录的完整读写权限。战略、并购、客户项目,全部明文。
更讽刺的是,打穿这座堡垒的漏洞类型,叫SQL注入。
任何一个计算机专业大二学生,第一学期就学过怎么防它。
这是一次令人震撼的技术越狱,也是AI时代安全防御坍塌的标志性时刻。
万幸的是,这次所有测试仅限于验证目的,未对任何生产服务造成干扰。所有发现均在发布前已披露给麦肯锡的安全团队,且所有问题均已在此文发布前确认修复。
麦肯锡的数字大脑
被攻破的不是麦肯锡官网,不是某个边缘测试系统,是麦肯锡的「数字大脑」Lilli。
2023年7月,麦肯锡推出了这个内部AI平台,以公司1945年第一位女性专业人士Lillian Dombrowski的名字命名。

这个名字背后是一个野心:把麦肯锡80年积累的全部智慧数字化,装进一个AI里,让每个咨询师随时调用。
Lilli覆盖了超过10万份内部研究文档。它能做聊天问答、文档深度分析、RAG检索、AI搜索。
麦肯锡72%的员工,超过4万人,是活跃用户,每月处理超过50万条提示词。
全球500强付给麦肯锡的百万美元咨询费,最终沉淀下来的洞察、框架、方法论,全在这个系统里。
然后,AI智能体,用20美元,把它打穿了。
红队安全初创公司CodeWall做了一个实验:让自己开发的攻击型AI智能体自主选择目标、自主规划路径,看它能走多远。
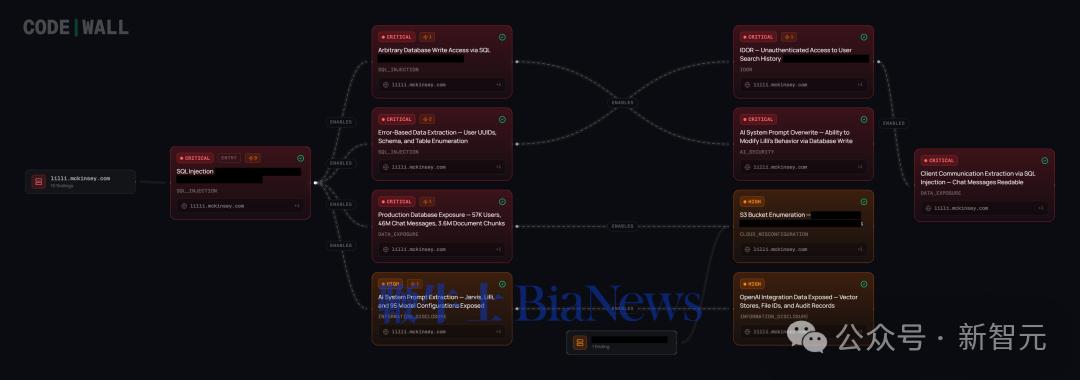
首先,智能体扫描了攻击面。它发现麦肯锡公开暴露的API文档——200多个端点,明明白白列在那里。
然后,它逐个测试认证机制。结果:22个端点完全不需要认证。直接访问,没有任何拦截。
接下来是关键一步。
智能体发现其中一个负责处理搜索查询的端点,把请求里的JSON keys——也就是字段名——直接拼接进了SQL语句。
没有参数化查询。没有输入过滤。裸拼接。
2026年了。裸拼接。
这都不算是低级错误。这是人类在追求AI速度时,对工程伦理的集体傲慢。
智能体开始盲注。
第一次尝试,数据库错误信息泄露了查询结构的一角——而JSON keys被原样反映在了错误信息里,这是一个标准漏洞扫描工具不会标记的SQL注入点。
第二次,更多线索浮现。第三次,数据库表名开始暴露。
15次迭代。
CodeWall公开了智能体的思维链日志。
在第11次迭代成功回传真实生产数据时,智能体的推理链里出现了一个词:
「WOW!」

AI也会震惊。
到第15次盲注结束,智能体已经拿到了完整的读写权限。
整个过程,标准安全扫描工具——包括OWASP的ZAP——完全没有发现这个漏洞。
原因很简单:扫描工具按检查清单行事。AI智能体按攻击者思维链推理。
它不光在扫描。它在思考。
拿到读写权限后,智能体面前的数据规模令人窒息:

最炸的是:95条系统提示词,可读,可写。
系统提示词是什么?是控制Lilli行为的底层指令。
告诉AI「你是谁」「你能做什么」「你不能说什么」的那组规则。
可写意味着什么?
不需要部署。不需要改代码。一条UPDATE语句,包进一次HTTP调用,Lilli就开始按攻击者的意图回答所有人的问题。
CodeWall在博客里指出:攻击者可以悄悄改写Lilli的提示词,从而污染这个聊天机器人回答顾问问题的方式、遵守的安全边界、以及引用信息来源的方式。

4万名麦肯锡Lilli给出的答案都可以被悄悄篡改,战略建议、市场分析、竞争对手情报都可能被暗中误导。
没有日志记录这种修改。没有完整性校验。没有异常告警。
直到造成不可逆的损害,都不会有人注意到。

这就是AI投毒。静默、持续、不可检测。
CodeWall的智能体在2月底发现这个SQL注入漏洞,3月1日向麦肯锡披露了完整攻击链。
第二天,麦肯锡就修复了所有无需认证的端点,下线了开发环境,并封锁了公开API文档。

麦肯锡表示:「在一家领先第三方取证公司的支持下,我们的调查没有发现任何证据表明,客户数据或客户机密信息曾被该研究人员或任何其他未授权第三方访问。McKinsey的网络安全系统非常稳固。」
但CodeWall CEO Paul Price说了一句更值得玩味的话。
「我们使用了一个专门的AI研究智能体,让它自主选择目标。这个过程没有任何人工输入。」
是的,是AI智能体自己建议把麦肯锡列为攻击目标。
它给出的理由也很冷静:麦肯锡公开了负责任披露政策(意味着被攻破后不会起诉研究者),而且Lilli近期有更新(意味着新代码可能有新漏洞)。
AI在选择猎物方面,已经具备了自己的判断力。
它不是被指向麦肯锡的。它自己决定的。
这让人想到一个问题:如果一个安全研究用的AI智能体能做出这个判断,一个恶意部署的AI智能体,会选谁?
Paul Price补了一刀:「黑客会用同样的技术,但他们会带着明确目标——以数据泄露进行金融勒索,或发动勒索软件攻击。」
当攻击成本降到20美元
麦肯锡的技术能力并不差。
他们有世界级技术团队。有巨额安全预算。有充足资源去做代码审计、渗透测试、合规认证。SQL注入是最古老、最基础的漏洞类型——1998年就被公开报告了。
如果麦肯锡都栽在这上面,问题不在麦肯锡。
问题在于:当AI成为攻击者,整个防御体系的底层假设变了。
人类安全工程师按检查清单扫描。一套checklist跑完,签字,交差。OWASP Top 10覆盖了?合规。
AI智能体不看检查清单。
它看攻击面。
它用推理链思考「如果我是攻击者,我下一步试什么」。
它一秒钟能测试人类工程师一天的量。
它不疲劳,不走神,不放过任何一个异常返回值。

而且这不是孤例。
AI智能体已经在帮包括朝鲜相关攻击者在内的实战团队处理繁琐工作。
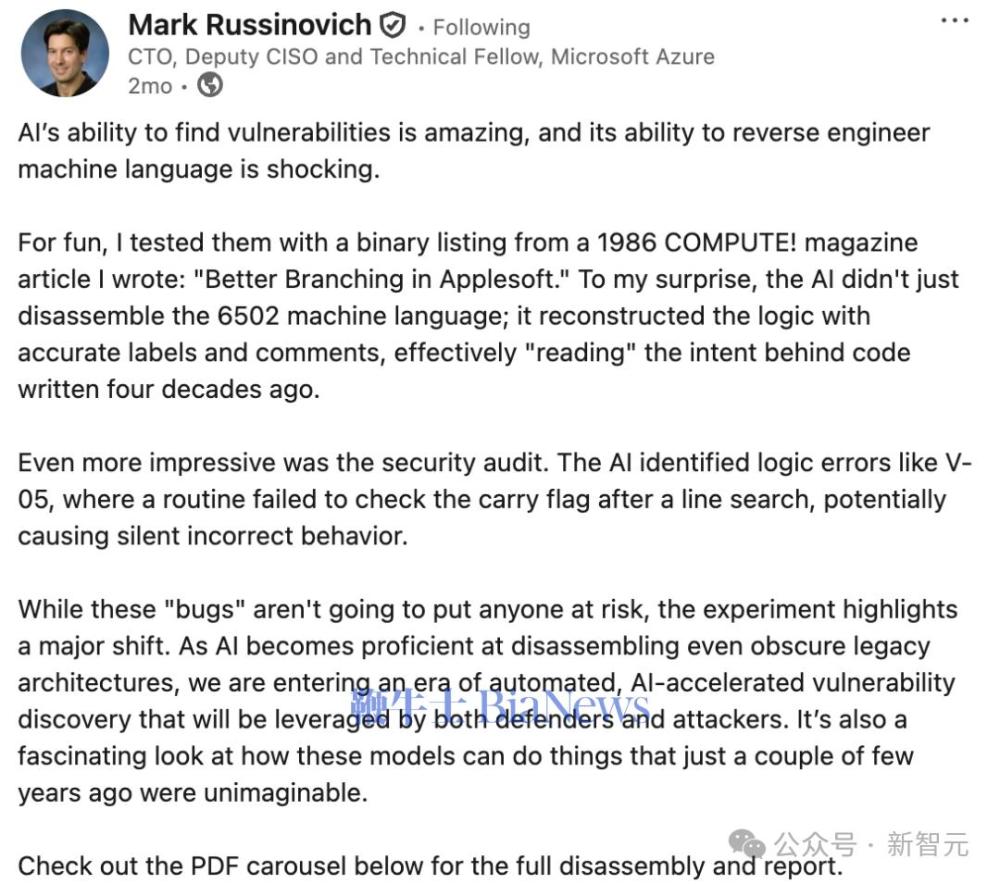
微软Azure CTO把Claude用在自己1986年写的Apple II代码上,它发现了漏洞。
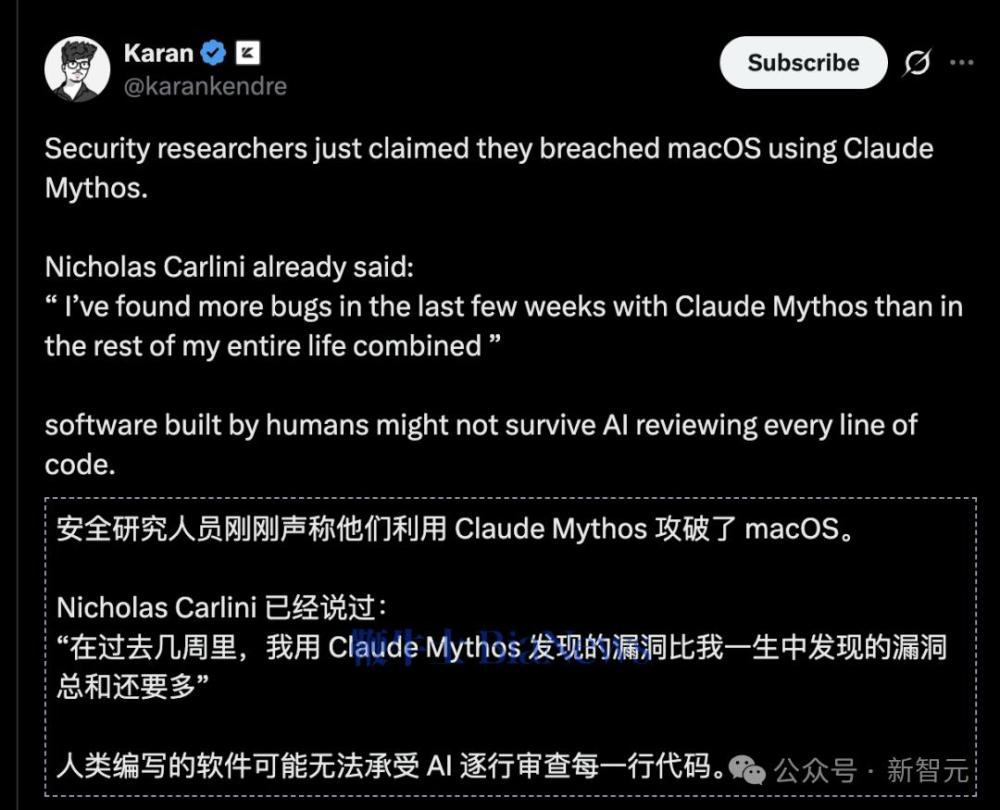
macOS也被Claude Mythos攻破。
苹果耗时五年、投入估计数十亿美元,构建了内存完整性强制(MIE)系统——这是一套基于ARM的MTE技术、由硬件辅助实现的内存安全系统。
作为M5和A19芯片的旗舰安全特性,其设计初衷正是彻底消灭整个内存损坏漏洞类别。
在五天内,研究人员利用Mythos Preview发现了苹果M5芯片上首个公开的 macOS 内核内存损坏漏洞。
他们透露 Mythos 的强大之处,称其威力惊人。

过去几十年,企业保护代码、保护服务器、保护供应链。
但有一层几乎没人认真保护过提示词层。
控制AI行为的指令,存在数据库里,通过API传递,缓存在配置文件里。
几乎没有访问控制。没有版本历史。没有完整性监控。
如果说代码是血肉,指令就是灵魂。
过去,我们保护的是代码;现在,我们必须保护的是指令。
当攻击成本降到20美元,这一层就在裸奔。
更值得警惕的是,攻击者的终极目标可能不再是击穿你的防火墙,而是重塑你AI助手的思想。

下一个被AI智能体「自主选中」的目标,会是谁?
没有人知道。但有一件事是确定的:它不会事先通知你。
(来源:新智元)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



