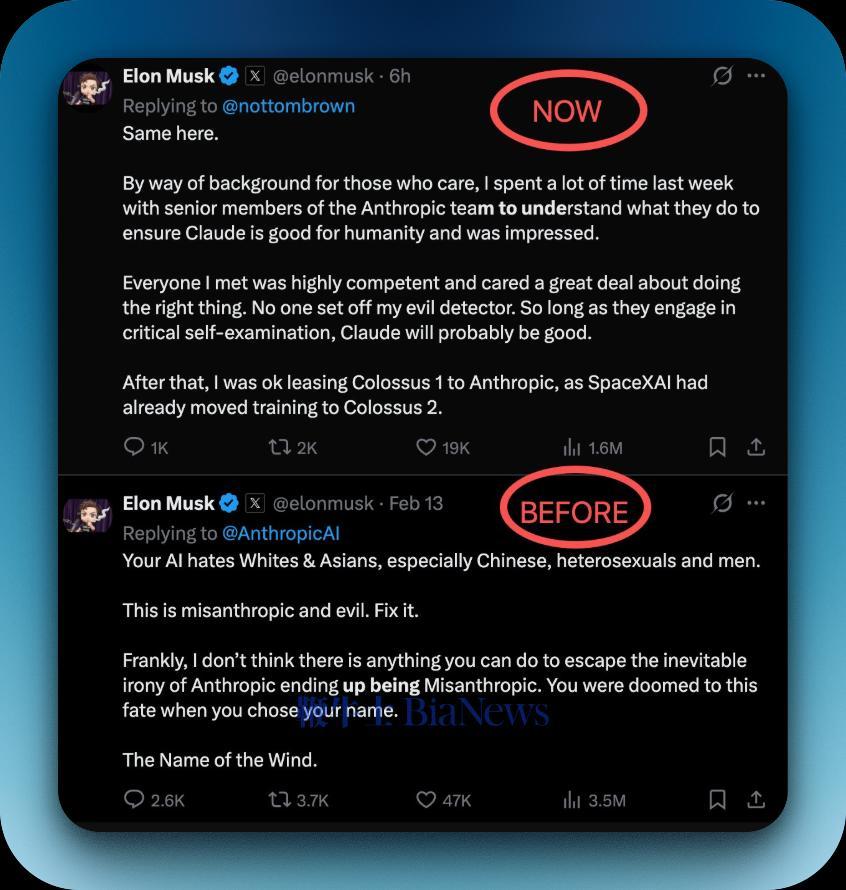
OpenAI 的两大宿敌 Anthropic 和马斯克,放下心中成见之后终于在月初结盟了。在此之前,Anthropic 和马斯克的关系并不融洽:今年 2 月,马斯克还在自己的 X 账号指责 A 社「woke」「邪恶」「反人类」(misanthropic),说这家公司「仇视文明」。事后来看,这次攻击并非马斯克清新脱俗的性格使然,而是 Anthropic 所做的某些事情触碰到他的神经,事出有因。在此之前,xAI 内部使用 Cursor 工作,但是今年年初员工发现,Claude 模型突然在 xAI 的 Cursor 公司账号里不能使用了。当时还在 xAI 上班的联合创始人吴宇怀,在全员信里是这么说的:「Anthropic 更新了政策,要求 Cursor 不得向其主要竞争对手提供 Claude 模型调用能力。」后来,xAI 整个联创团队都散伙了,实体也跟 SpaceX 合并,成为「SpaceXAI」。但当时,吴宇怀在信中写了一句话,颇为有趣:
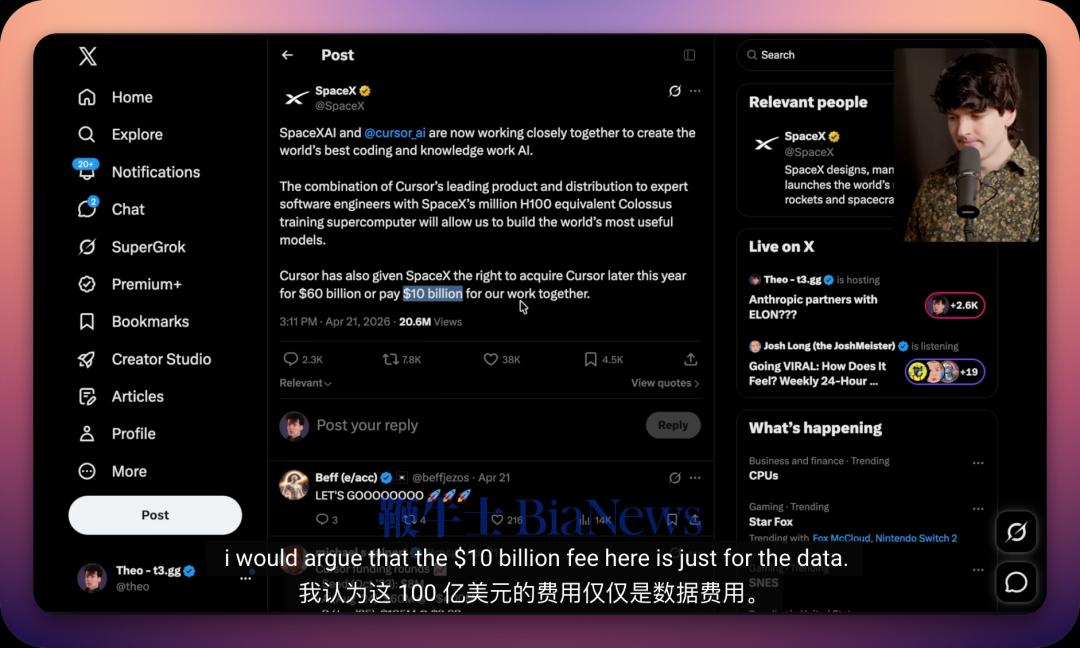
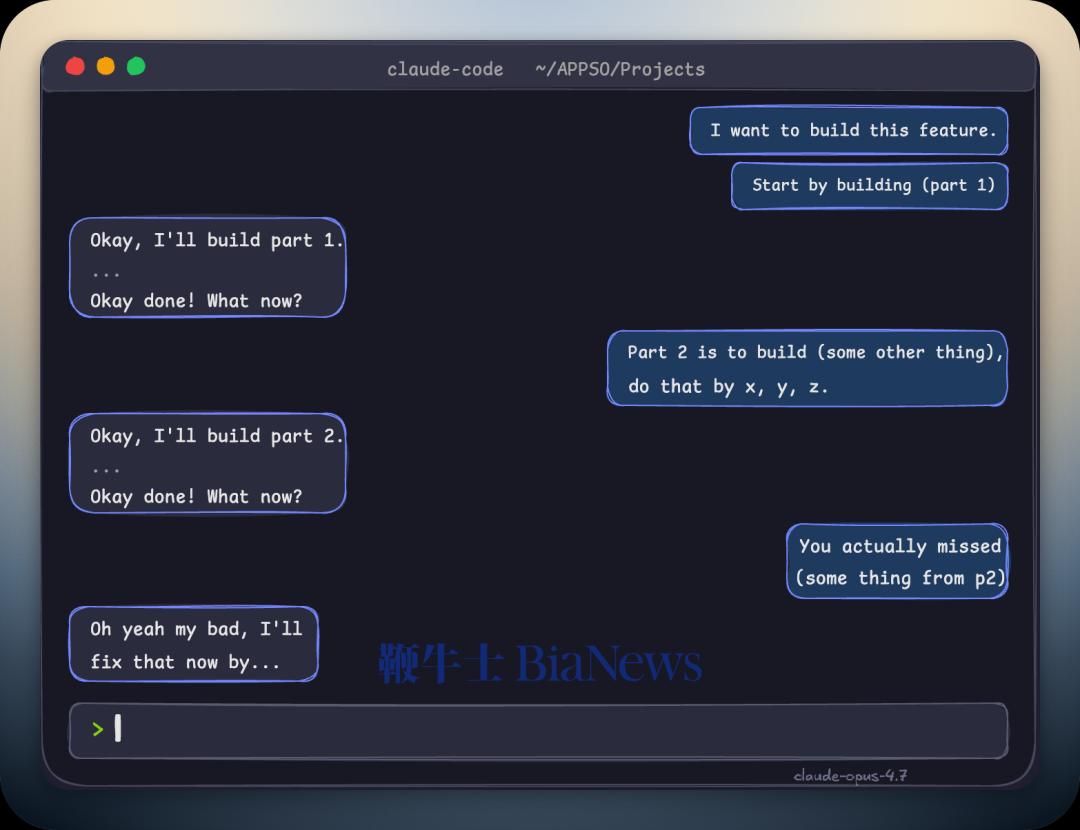
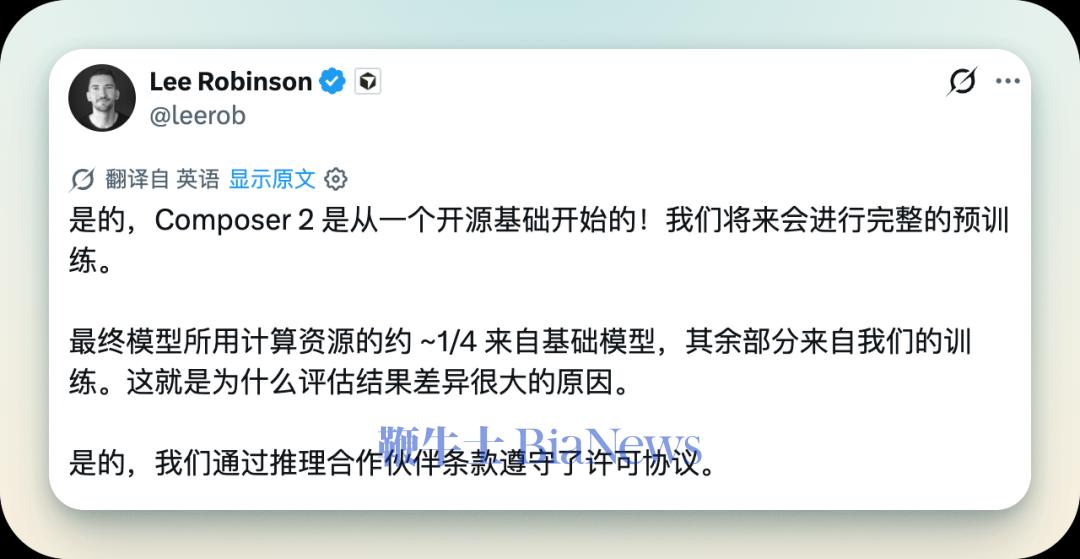
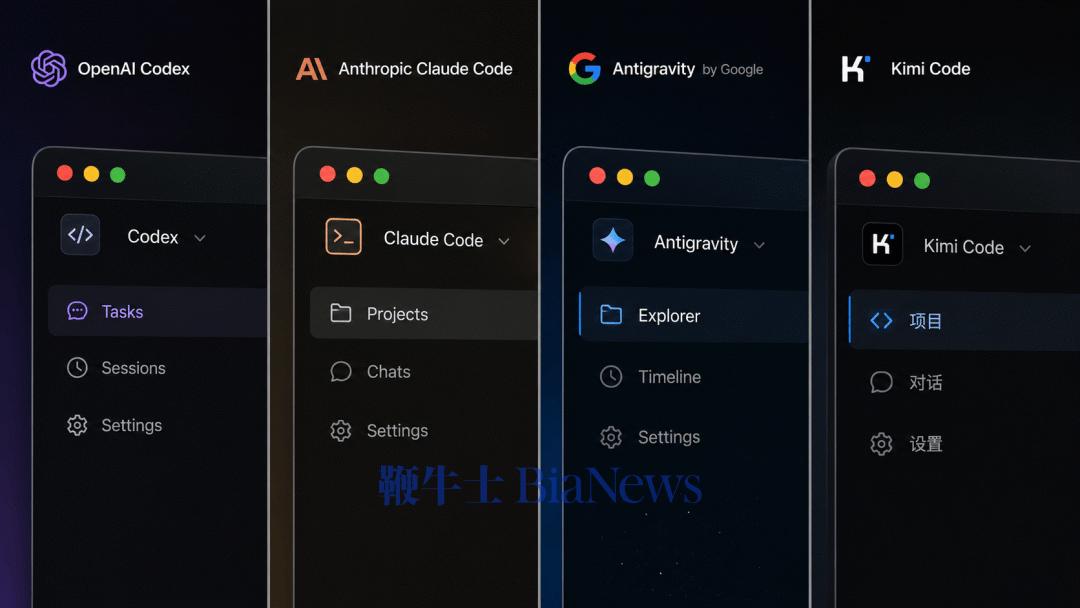
「这是坏消息也是好消息。我们的生产力会被影响,但这也敦促我们开发自己的编码产品和模型。」为什么当时 xAI 的高层认为,开发自己的编码产品是关键?后来发生的事情,大家都知道了。xAI 的联创团队悉数跑路,马斯克一气之下对 Cursor 使用了钞能力必杀:上个月底,SpaceX 和 Cursor 共同宣布,将在编程和知识类工作 AI 模型的训练上,展开前所未有的战略合作;并且,SpaceX 还获得了以 600 亿美元收购 Cursor 的权利,或向后者支付 100 亿美元合作费用。注意编程这个关键定语,后面还会 call back.最近,我看了一条 Cursor 早期投资人、Anthropic 大喷子、T3 创始人 Theo Browne 的视频。本来点进去是看他喷 A 社和 SpaceX 怎么蝇营狗苟,结果没想到,却看到了关于 SpaceX + Cursor 合作的,一个既另类却又极度合理的分析:不说 600 亿的收购,就只说 100 亿的合作费——Theo 在视频里表示,自己认为「哪怕只是交换到 Cursor 的用户数据,这 100 亿也值回票价了。」所以是什么数据?如果你也去看 Theo 这条视频,他会讲得非常清楚。但为了节约时间,我们在这里简单概括一下:我们和 AI 的对话是一来一回的,你提出问题/需求,他给你解答;coding agent 同理,只不过返回的是代码。一次高质量的对话,整个过程,包括用户提示、模型思考、agent 规划、输出代码、验证——所有这些东西合起来,可以称为一个完整的 Agentic Loop——就成为了高价值的训练数据,再喂给模型去进行强化学习,就能进一步提高模型在实战场景下的表现水准。Cursor 有的,SpaceX 想要的,就是这些数据。答案很简单:作为模型厂商,这种高质量数据的最直接来源,只能是你自己开发的 coding agent 产品——也即 Anthropic 的 Claude Code、OpenAI 的 Codex、Kimi 的 Kimi Code。现在你应该明白了,为什么被 Anthropic「封号」之后,吴宇怀会在全员信里提出开发 xAI 自己的 coding 产品和模型这件事了。这件事 xAI 在当时已经看清楚了:没有自己的编码产品,就没有高质量的强化学习数据;没有高质量的数据,就训练不出真正实战能力强的 coding 模型。虽然有点暴论,但现在我们可以点题了:模型厂商想做出来真正能打的编程模型,做自己的 coding agent 产品是唯一的路径。大语言模型像个水晶球,用全网的语料训练出来,似乎能够解答万物,但并不代表它在所有问题上都能给出高质量的答案。用 GitHub 上数以亿计的代码条目训练,当然也能训练出 coding 模型。这是「学习结果」的逻辑,也是没问题的。毕竟编码任务的结果是可以验证的:代码能不能运行,测试能否通过,结果摆在那里。但是,通往结果的过程,是一个设计多步骤决策、错误纠正、意图对齐的复杂链条。每一次用户的接受、拒绝、补全、撤销、追问、甚至当模型好几次都搞不定或者完全搞错时的辱骂——都是这一链条上的过程信号。强化学习有两种监督方式,一种叫做结果监督,只看最后是否跑通。但是结果监督会催生「奖励黑客」的现象:模型为了能跑通可能写出冗余、脆弱、带逻辑漏洞的代码,但因为测试过了,模型以为自己学对了。而另一种叫做过程监督,对推理路径上的每一步进行打分。上述这些过程信号,只有在 coding agent 运行环境里才能诞生。GitHub 仓库里只有结果,哪怕是去看单独的提交历史,看 PR,都找不到有效的过程信号。在缺乏有效、自主可获得的过程信号的时候,一些模型厂商会采用「蒸馏」的方式,这个事情大家应该已经知道了。蒸馏的逻辑很简单,给同样的输入,老师模型输出什么,学生模型就学着输出什么。但是通过蒸馏,即便可以获取到思维链,得到的仍然更像是结果,而非被蒸馏的老师模型内部的概率分布。一旦学生在推理中偏离了老师的轨迹,哪怕一个 token 不符合,都有可能发生偏离。这背后是强化学习的基础限制:策略梯度定理要求,优化样本最好由当前正在优化的模型自己去产生。这种数据叫做 on-policy 数据。而通过蒸馏别家模型,在别人的产品里产生的数据,来训练自己模型,都属于 off-policy 数据。模型当然可以从中学到东西,但学不到老师模型内部的概率分布信息。而像 Cursor 这样自己就是 coding agent 产品的公司,掌握着最真实、有效、高质量的训练数据。Cursor 产品本身,就是 coding 模型在实战环境中的最佳训练场。我们可以通过 Cursor 年初的「翻车」,来证明这个逻辑。APPSO 读者应该记得,年初 Cursor 发布了 Composer 2,号称「下一代专用编程模型」,技术报道写的相对保守,自报家门是新模型,也没有提供具体的模型底座信息。结果很快,网友就在公开代码片段里发现了 Kimi 的模型 ID,截图传遍了开发者社群,逼得 Cursor 副总裁 Lee Robinson 出面澄清:「Composer 2 确实是从开源底座出发的。最终模型大约只有 1/4 的算力来自底座,剩下 3/4 是我们自己训出来的。」几小时后,Cursor 联创 Aman Sanger 也跟着发了一条道歉:「一开始没提 Kimi 底座是个失误。」五天后,Cursor 放出了完整的 Composer 2 技术报告,显示底座的确是 Kimi K2.5,授权方则是 Firworks AI,大致流程是在 K2.5 上做训练,再继续做大规模强化学习(RL)。但关键之处在于,Composer 2 的 RL 是运行在真实的 Cursor 会话当中,使用与生产部署完全相同的工具和 harness。Cursor 将这套流程叫做「实时强化学习」(real-time RL),也即将模型的 checkpoint 直接部署到 Cursor 生产环境中,观察用户的响应,收集数据,聚合成奖励信号,最快可以每 5 个小时迭代一次模型版本,然后继续部署到 Cursor 里,循环往复。最极致的案例是 Cursor 的自动化代码补全功能 Tab,每天处理超过 4 亿次请求,每当用户输入字符、移动光标时,模型都会预测下一步动作,如果预测置信度高,则显示建议,用户按下 tab 即接受自动补全。该功能采用的是在线强化学习,在行业内极具特色。Cursor 可以以极高的频率(最快可达每一个半小时到两小时)更新 Tab 的模型能力给用户,直接在产品内收集 on-policy 数据进行训练。这种高频、接近实时的反馈回路,让 Tab 可以学习到极其微妙的用户意图。Cursor 方面透露,这种方法让 Tab 建议的拒绝率降低 21%,接受率提高了 28%。回到 Composer 模型本身。在事情搞清楚了之后,一些 Kimi 员工也删掉了之前吐槽的的推文,Kimi 官方账号发表了祝贺。一家估值 600 亿美元(基于马斯克给的数字),不做自己的模型基座的 coding agent 应用层公司,仍然可以通过产品自身的数据飞轮,RL 出超越基座模型的专有编程模型。所以预期说 Cursor 翻了车,不如说这反而是 coding agent 产品重要性的绝佳例证。Cursor 在另一篇关于实时 RL 的文章里写到:「(训练编程模型)最大的困难在于建模用户。Composer 的生产环境里不只有执行命令的计算机,还有监督和指导它的人。模拟计算机容易,模拟使用它的人却很难。」这句话,现正在逐渐成为了在编程模型方面走在前沿的模型厂商之间的共识。如果你去看 benchmark 榜单和用户普遍评价,会发现哪些头部的厂商都在发力做自己的 coding agent/编程产品。区别只在于谁离用户更近。我们以 SWE-bench、LLM-Stats 等相对权威的榜单为例,Claude、GPT、Gemini、Kimi 等模型基本霸榜前十,清一色都是有自己开发 coding agent 产品(包括 CLI、IDE、集成 coding agent 的桌面客户端)的模型厂商。在部分榜单上会出现少数反例,如 Meta (Muse Spark)、Minimax、DeepSeek 等,没有开发自己的 coding agent。不过你会发现,这些反例模型,在更加接近真实场景、避免污染的更权威 benchmark 上就很难上榜了。以 DeepSeek 为例,它在 SWE-bench bash only 上分数是 70%,排名第九,在 SWE-bench Pro 上分数却掉到了 15% 左右。OpenRouter 的真实流量数据可以解释这种反差:该平台 2025 年报告显示,Claude token 消费 80% 以上用于编程和技术任务,而 DeepSeek token 消费主要集中于闲聊和角色扮演。没有自家 coding 产品的厂商,在一些 coding 任务 benchmark 上能挤进头部,但在更难的真实工程 benchmark 上,在用户用 token 消费投票的真实流量中,都会原形毕露。不仅是 Cursor,Anthropic 在 2025 年 11 月发的一篇论文里,也明确透露自己在做一模一样的事情:「我们在 Anthropic 自家的真实生产编程环境上做训练。」也即 Anthropic 把自己员工使用 Claude Code 的交互数据,反哺给 Claude 模型用来训练。在 AI 的演进历程中,生产要素的定义发生了深刻的位移。传统三大核心要素——算力、研究、训练数据,虽然在总量上持续增长,但在结构上已经出现了严重的失衡。今天的各大 AI 巨头显著提高了在算力上的资本支出 (CapEx),让算力基建成为了当前舆论的主旋律。但实际上,特别是在编程范畴内,随着 GitHub 仓库、StackOverflow 等互联网公开代码数据被基模厂商「竭泽而渔」式地利用,模型在代码生成与逻辑推理上的边界开始逐渐显现。
这也是为什么,行业共识正在逐渐转向一个冉冉升起的新战略高地:对于任何希望掌握顶级代码能力的模型厂商而言,建立自有的 coding agent 产品早已不再是可选的商业路线,而是确保底层模型可以持续进化的核心生命线。
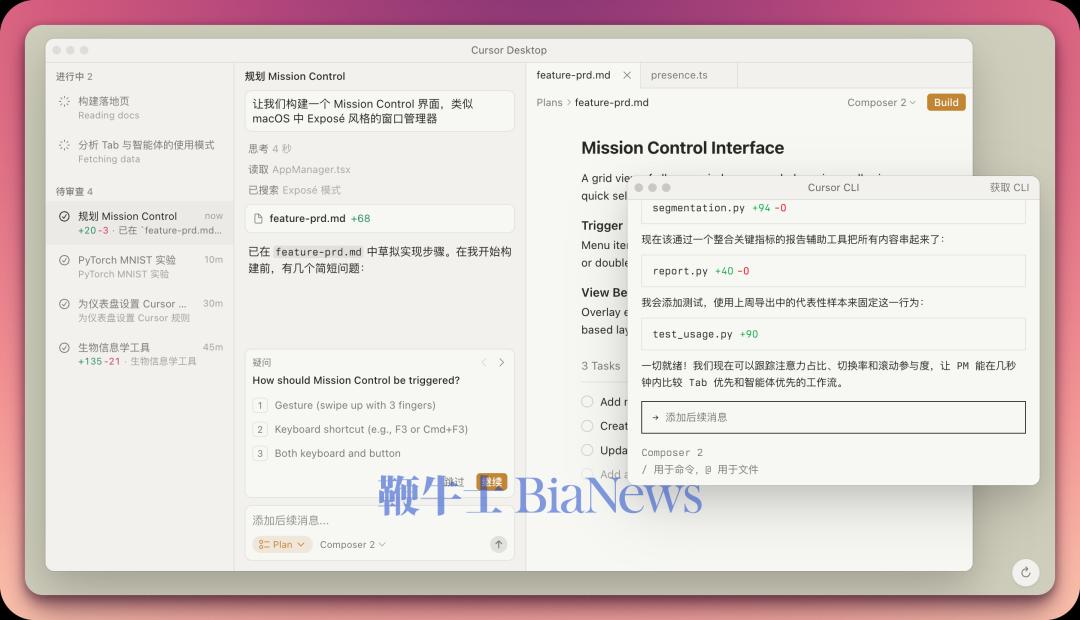
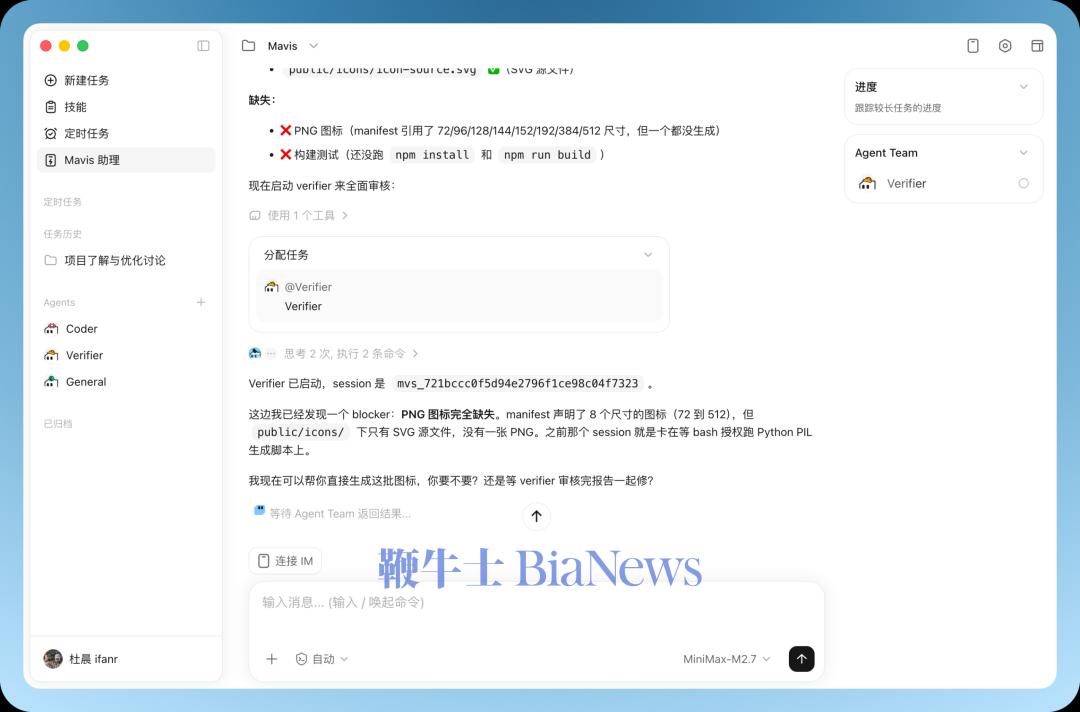
正如前面 APPSO 论证的那样,单纯学习公开数据等于只学习成功者的结局,却无法了解成功的路径,这绝对不是正确的成功学应该有的样子。在真实的编程环境中,知道发生了什么错误、怎样发生的、如何正确地理解和高效地实践需求等等——了解正确过程的价值,远超于得到正确结果本身。只有拥有自己的编码产品,模型厂商才能获取高质量的「过程监督」信号,从而在编码/推理能力的下一阶段竞争中,确保自己仍有技术护城河——否则就不得不像 SpaceXAI 那样,花钱去跟 coding agent 产品公司去合作。然而并不是所有模型厂商都跟马斯克一样有钱,以及 2026 年开始的巨头势力划分、结盟与领地的争斗会变得更加激烈,当一家缺乏自主 coding 产品的模型厂商终于回过味来的时候,恐怕已经没有足够的合作伙伴可以挑选,合作的价格也将水涨船高。美国模型巨头的情况大家普遍比较熟悉了,在此不赘述。APPSO 也注意到,国内的主流模型厂商和 AI 巨头当中,绝大部分都已经在 coding agent 产品上有所布局。国内巨头公司主要以原生 AI IDE 或 IDE 插件的思路在做:字节跳动去年很早就布局了 TRAE、阿里巴巴的 Qoder、腾讯的 CodeBuddy、百度的文心快码 Comate 等。AI 小龙公司中,月之暗面是最早开发独立 coding agent 产品的公司,主要以 CLI 界面的 Kimi Code 为主——不过 Kimi 此前有透露过,在原生编程产品这件事上,CLI 不会是终局。另一种实现思路是模型厂商自行提供 API 服务、Coding Plan。这样,不论用户使用何种 AI 开发环境,模型厂商都可以通过服务器端的 API 记录来获取最大程度接近于原生 coding 产品的过程数据。但这也只是接近,并非完全相同。核心在于,服务器端 API 的请求-响应日志,与深度继承的产品交互轨迹相比仍有很大差距。自建产品的厂商(例如 Cursor、Claude 桌面端、Codex)拥有最直接的显式反馈信号,而 API 侧是相对模糊的隐式推断。简单来说,API 侧能看到用户请求和响应,但用户最后是否采纳了这段代码、代码能否跑通、引发了什么样的 bug,API 侧对此是一无所知的。他们无法了解到用户最终行为这一关键的标签,从而无法实现最高质量的强化学习。形而上来讲,语言即世界,代码即方案。代码可以表达这个世界上绝大多数的任务,代码也会成为头部的放大器,让最顶尖的人才放大数倍的生产力。只有最顶尖的 coding 模型才配得上最顶尖的人才。如果领先的模型厂商不重视 coding,势必将会掉出第一梯队。当然,事实上每家模型厂商都不会不重视 coding——而是说,在新的范式下,哪些没有自主可控的原生 coding agent 产品,极有可能逐渐落后于有产品的厂商。就在前几天,MiniMax 也发布了桌面客户端产品的重大更新:带有全新多 agent 编排架构的 Mavis 功能,并且也让客户端显著改善了对 coding 任务的支持。
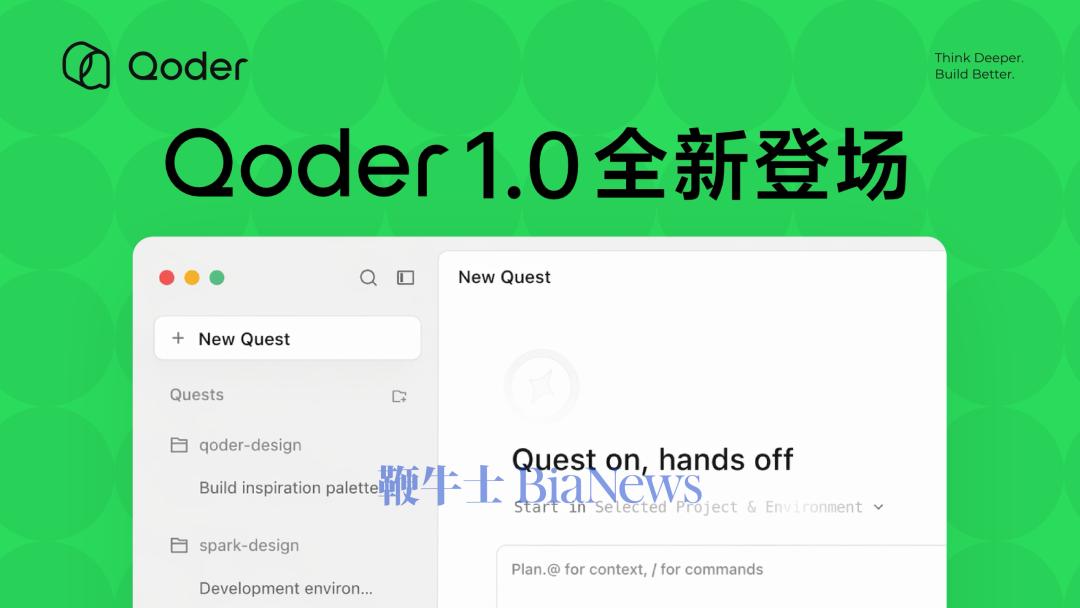
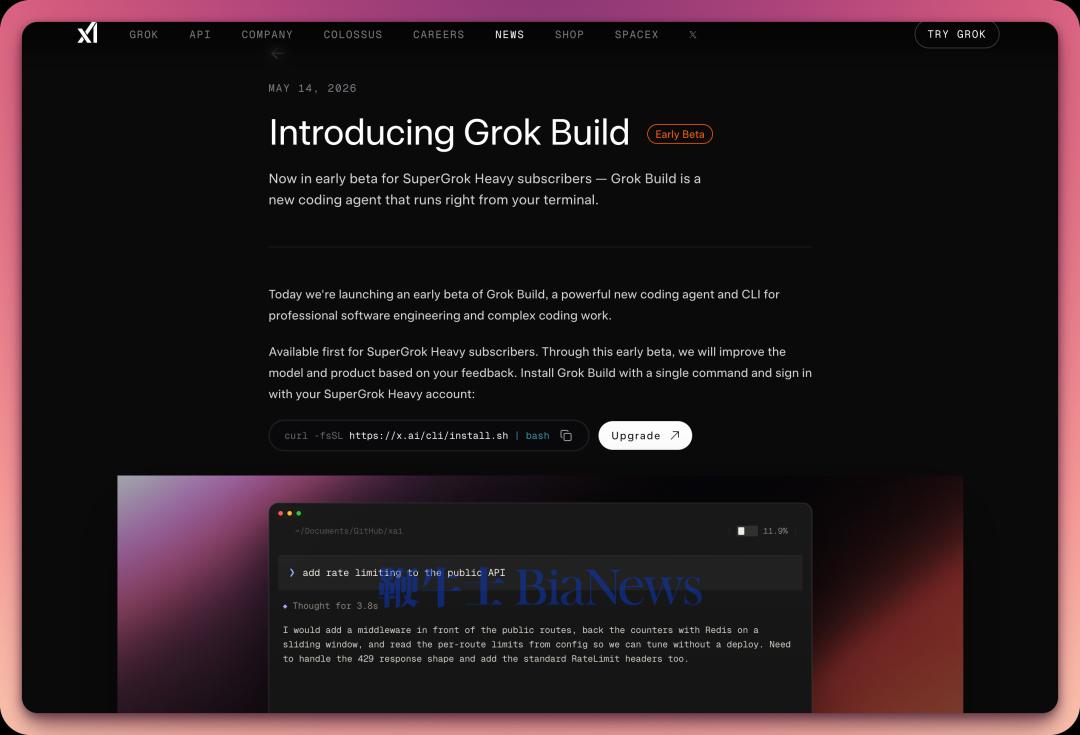
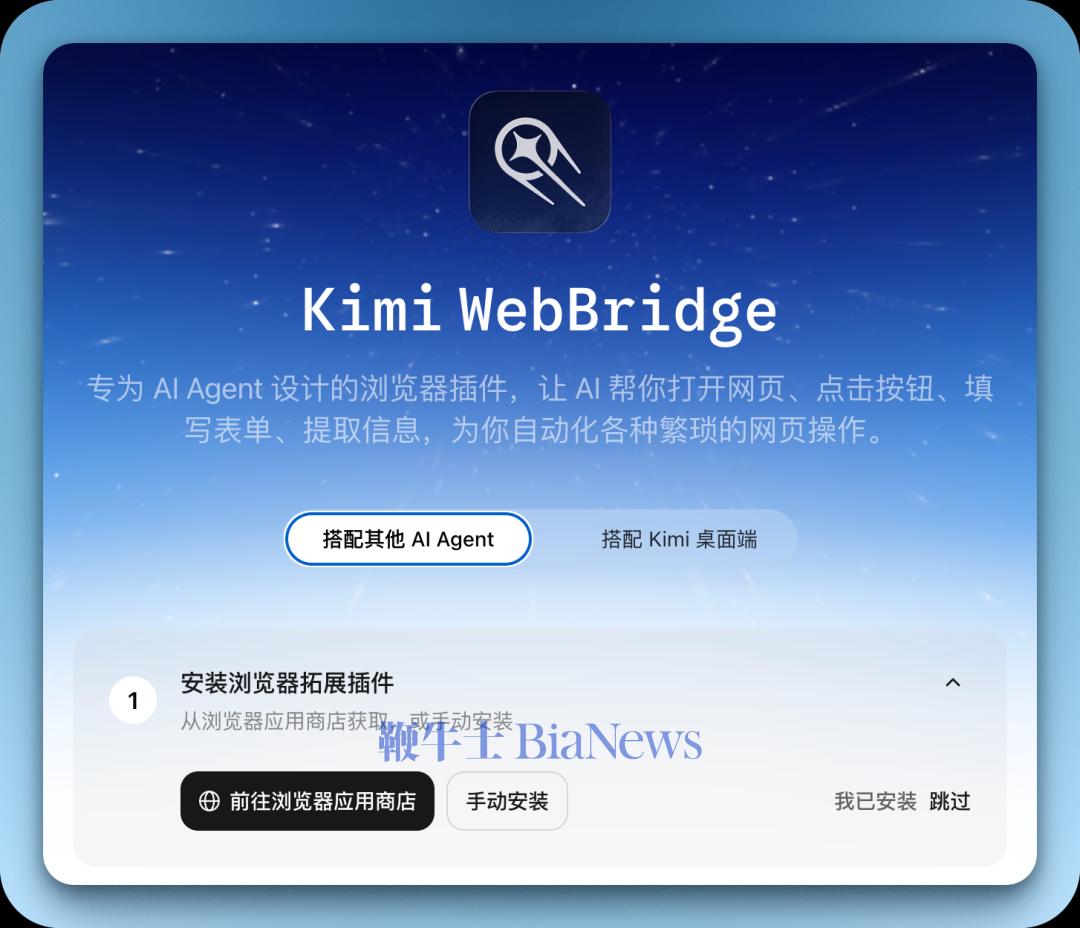
此前 MiniMax 只是推出了桌面端,但没有加入原生 coding 和 agent 功能。紧接着,在 5 月 15 日,阿里巴巴正式发布了 Qoder 1.0——这个产品从 IDE 的形态正式升级为一个完整的 Agent 产品(阿里的官方叫法是智能体自主开发工作台)。与此同时,xAI 的 Grok Build CLI,也终于正式推出了。没错,就是 xAI 年初被 Anthropic 和 Cursor 封号之后,他们自己捣鼓出来的那个 coding agent.看来,大家都认为 Cursor、Codex 和 Claude 桌面端走在正确的道路上。把话题从 coding 扩展到 agent 本身,情况也是一样的。编码任务的轨迹数据,在公开语料中确实还是能找到一些的(比如 GitHub 的提交记录/PR,尽管质量并不高)。但是 agent 任务的轨迹数据,包括并不限于移动和点击鼠标、操控触屏、填写输入框等,却无法在公开语料中找到。所以我们会看到,即使在 agent 操作的最小实现路径——浏览器插件上,即便是这么个看起来一点都不高端的东西,几乎每家模型厂商都会做自己的。OpenAI 早在 2025 年 1 月就做了 Operator——与其说它是一个「AI 自动操作浏览器」的产品,不如说本质上就是一个大规模的数据收集装置。每一位试用 Operator 的用户,都在免费为 OpenAI 提供 on-policy 数据。后续 OpenAI 还衍生出 ChatGPT Agent 以及新版 Codex 桌面端;Anthropic 也是同理;最近 Kimi 不声不响地也做了一个叫做 WebBridge 的项目,其实就是一个浏览器插件。即便是在过去两年里动作最克制的中国模型巨头深度求索,也在最近开始展露出对 Agent 的兴趣。CEO 梁文锋此前接受采访时曾经提到这样的观点:数学和代码是AGI天然的试验场,有点像围棋,是一个封闭的、可验证的系统,有可能通过自我学习就能实现很高的智能。
这句话的潜台词,是 DeepSeek 一直把 coding、Agent 当研究试验场,而非商业化方向。
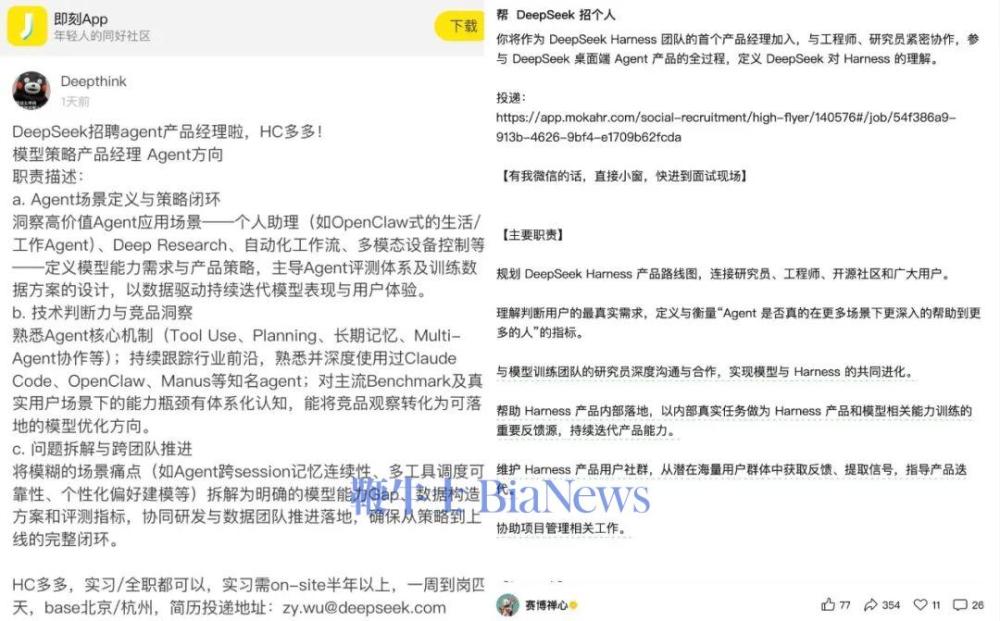
但是在今年 3 月,DeepSeek 一次性放出了十几个 Agent 相关岗位,包括首次出现的模型策略产品经理(Agent 方向)等。当时的 JD 职责涵盖「主导 Agent 评测体系以及训练数据方案的设计」,要求中包括「深度使用 Claude Code、Manus」等产品。APPSO 注意到,近期深度求索发布了 Agent 产品经理、Harness 产品经理等职位招聘信息——很显然,DeepSeek 要做独立、原生的 Coding/Agent 产品了。此前资料显示,DeepSeek V3.2 的训练过程中引入了近两千个合成的 Agent 训练环境和八万多条复杂指令。但是看起来,靠合成的训练数据只能带 DeepSeek 走到这里了,剩下的是合成不出来的部分:真实用户在真实环境里的真实成功和失败,必须靠自家的 agent 产品才能拿到。DeepSeek 以一种极度克制的方式做了三年模型以及模型产品(直到上个月才终于在官网加入了多模态能力)。但是在今天来看,在编码类任务上,DeepSeek 拿 SOTA 越来越难了,即便此前拿到也会在不久后被超越。当助理依靠研究的路径支撑不住飞轮的时候,DeepSeek 终于行动了。根据 The Information 报道援引知情人士报道,在接受马斯克 600 亿收购/100 亿美元合作的同时,Cursor 表示不会与 xAI 合作开发新的模型,而是仍将聚焦于优化自己的 Composer 模型。这意味着,即便被马斯克买通甚至收购,Cursor 仍然要保留自己数据飞轮的主体性。当所有顶级模型厂商都做了自己的产品,所有顶级产品也都开始训练自己的模型,「模型公司」和「产品公司」的本就不太清楚的界限,似乎越来越不存在了……




 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握


 微信好友
微信好友
 朋友圈
朋友圈
 鞭牛士公众号
鞭牛士公众号
 鞭牛士微博
鞭牛士微博