

《晚点 LatePost》独家获悉,Kimi (月之暗面)即将完成新一轮 20 亿美元融资,投后估值突破 200 亿美元。本轮融资由美团龙珠领投,中国移动、CPE(中信产业基金)等参投,其中仅龙珠就出手超 2 亿美元。 今年 1 月和 2 月,Kimi 刚密集完成 3 轮融资 ,分别融了 5 亿美元、 7 亿美元和 7 亿美元。算上这笔最新融资,不到半年里,Kimi 融资超 39 亿美元,最新估值相比去年 11 月的约 43 亿美元翻了 4 倍有余。 至此,Kimi 累计融资额已超 376 亿人民币,成为大模型创业公司中累计融资最多的公司。算上 IPO 募资,MiniMax 累计融资约 150 亿人民币,智谱约 130 亿人民币。截至 5 月 6 日午间休市,MiniMax 市值约 2100 亿人民币,智谱约 3470 亿人民币。
美团龙珠合伙人王新宇告诉我们,K2.5 模型更新后,Kimi ARR(年度经常性收入)在今年 3 月初突破 1 亿美元,在 4 月继续增长至超 2 亿美元,付费订阅和 API 调用都在加速。
完成新融资前夕,Kimi 最新模型 K2.6 在 4 月 20 日晚发布并开源。K2.6 强化了编程能力和 Agent 集群能力,可支持最多 300 个子 Agent 协作,Kimi 也开始同步测试 Claw 群组新功能。
这此前的一年多,Kimi 经历了战略、士气和投融资行情的多方面触底反弹。
2025 年 1 月 20 日,Kimi 发布推理模型 Kimi K1.5,对标 OpenAI o1 。同一天,DeepSeek 发布并开源 DeepSeek-R1。
尽管 K1.5 在一些 benchmark 上超越了当时的领先模型 GPT-4o 和 Claude 3.5 Sonnet ,但市场注意力几乎全被 DeepSeek 吸引。随后的 2025 年春节,DeepSeek 以 0 投放斩获数千万日活,一举超越 2024 年大额投放的 Kimi,也一度超越了字节豆包。
那是 Kimi 的艰难时期。2025 年春节后,kimi 有了 3 个重要变化:
以 “持续拿到 SOTA(模型最佳表现)” 为最优先级目标。 大幅减少 C 端投放。 从闭源走向开源。 那之后,Kimi 在方向选择和具体技术成果上都有不错的表现。 选定 coding 和 Agent:“生产力优先” 落到了行动 和智谱类似,Kimi 是中国公司中较早开始侧重编程能力的团队,而编程又是通用 Agent 的最核心能力。 这与杨植麟一直说的 “生产力场景优先”、“效率场景优先” 一脉相承。但在 2024 年,Kimi 动作依然发散,也尝试过海外 to C 产品和视频生成。 2025 年后,Kimi 更加聚焦。这一年 7 月开源的 Kimi K2 和 2026 年 1 月至今的 K2.5 与 K2.6 都在持续强化编程和 Agent 能力。 其中,K2 是一款 Kimi 借鉴 DeepSeek 经验,补课预训练能力后的模型,采取了与 DeepSeek-V3 类似的 MoE(混合专家模型)与 MLA(Multi-Head Latent Attention,多头潜在注意力)架构,把总参数扩展到 1T(万亿参数),强化了编程和多轮工具调用等 agent 能力。2 个月后,Kimi 推出 Agent 功能 “OK Computer”(后改名 Kimi Agent)。K2.5 则首次引入视觉能力,并开始支持智能体群模式。 Artificial Analysis 的综合智能指数。 Kimi K2.6 低于 OpenAI、Anthropic 和 Google DeepMind 三家公司的新模型,高于 Meta 的 Muse 和 xAI 的 Grok。 K2.5 对编程和 Agent 的优化适用于 OpenClaw(业内称 “龙虾”),Kimi 也迅速在 2 月 15 日推出了云端龙虾 Kimi Claw,支持低门槛的一键部署。 模型进化叠加产品更新,Kimi 今年以来的收入、订阅用户数大幅增长。 据全球支付平台 Stripe 数据,自 2026 年 1 月底以来,Kimi 近 20 天收入超越 2025 年全年总和。其个人订阅用户 1 月支付订单数环比增长超 8000%,2 月环比再涨超 120%。 据 Similarweb 数据,Kimi 海外 API 开放平台在 K2.5 发布后日均访问量暴涨 10-20 倍。 MuonClip、Attention Residuals,技术影响力显现 在具体技术成果上,2025 年年初,Kimi 在 16B 的 Moonlight 模型上验证了 Keller Jordan 2024 年开源的 Muon 优化器(原初版本是在 1.5B 模型上做验证),后来又在 1T 规模的 K2 上提出 Muon 的一个改进版 MuonClip,后被广泛采用。 Moonlight 共同一作之一 Jingyuan Liu 已于 2025 年年中加入 Meta,目前任职于 Meta 超级智能实验室(MSL)。 2025 年 10 月,Kimi 推出实验性的线性注意力架构模型 Kimi-Liner。该模型在开源的 DeltNet Attention 基础上做了进一步修改。 为更好探索线性注意力,Kimi 从 AI 研究者杨松林发起的 FLA 线性注意力开源社区中招募了贡献颇多的活跃开发者张宇和陈广宇。张宇是苏州大学计算机科学与技术学院博士,陈广宇是一位高中生。 2026 年 3 月,Kimi 提出 Attention Residuals(注意力残差),它引入了 Transformer 中的注意力机制,解决传统残差连接(Residual Connection)的信息稀释、训练不稳定等痛点。残差链接是深度神经网络已使用十几年的一项基础技术。马斯克在推特转发了这个成果,“Impressive work from Kimi”。 Attention Residuals 有三位核心作者:Kimi 从 FLA 社区挖掘的陈广宇和张宇,还有人称 “苏神” 的苏剑林。他是大模型中广泛使用的 RoPE(旋转式位置编码)的作者,独自一人在广州工作。 Attention Residuals 与 DeepSeek 2025 年年底的 mHC(Manifold-Constrained Hyper-Connections 流形约束超连接) 想实现的效果有相似之处。而 mHC 改进的 HC 又是字节跳动 Seed 团队提出的。 HC、mHC、Attention Residuals,这些接连出现的技术改进是中国 AI 人才密度与竞争烈度的产物。 从 “太贵” 到 “好便宜” 2024 年底,《晚点 LatePost》曾在《中国大模型生存战:巨头围剿,创业难熬》里提到,面对 “会跳舞的大象” 字节,中国一批大模型创业公司压力巨大。 18 个月来,两个关键事件使创业公司的 “一线生机” 逐渐打开。 一是 DeepSeek-R1 使开源模型生态真正繁荣、活跃,众多开源模型之间的技术交流加速了大模型进化;二是 Agent 应用加快普及,同期上市的智谱、MiniMax 股价趁势大涨,刺激更多资金涌向大模型行业。 目前,MiniMax 和智谱的市值在 2000~4000 亿人民之间波动。这让估值约 1400 亿人民币的 Kimi 成为一个热门投资标的。 接下来,这些模型公司面临的重要课题是继续保持模型 SOTA 和验证 “token” 经济的商业模式。 模型能力的核心是人才。2026 年初,Kimi 创始人杨植麟在全员信中提到:2026 年公司平均激励将是 2025 年的 200%,并计划大幅上调期权回购额度 。 2026 年 4 月初,《晚点 LatePost》也报道了 Kimi 给实习生发期权 “穿越计划”。由于 Kimi 估值在数月内就翻了 4 倍多、且尚未上市,它的期权变得有吸引力。 尽管如此,Kimi 现在正面临不小的人才压力,由于其在编程、 agent 等领域的优异表现和这一应用方向的白热化竞争,Kimi 相关人员已成为竞争对手的重点挖角对象。 而在商业模式上,中国大模型创业公司普遍在用两种方式赚取收入:一是通过 API 提供模型,按 token 实际用量来收费;二是基于自己的模型做应用,获取按月/年定额的付费用户。能否及时获得高质量算力,能否以高效推理控制好成本,以及能否用产品体验带来 “溢价” 是证明商业模式的关键。获得足够多的钱是这一切的基础。(转载自晚点LatePost)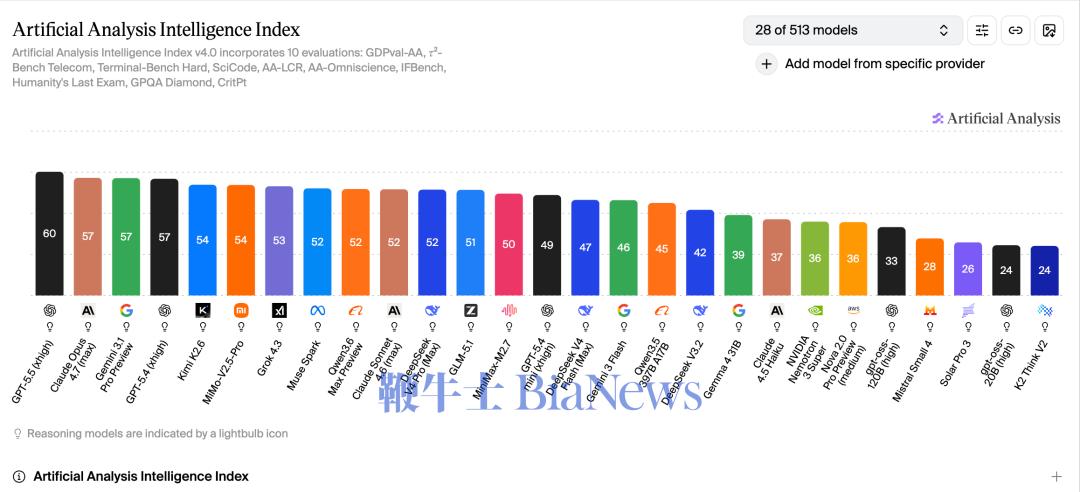
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



