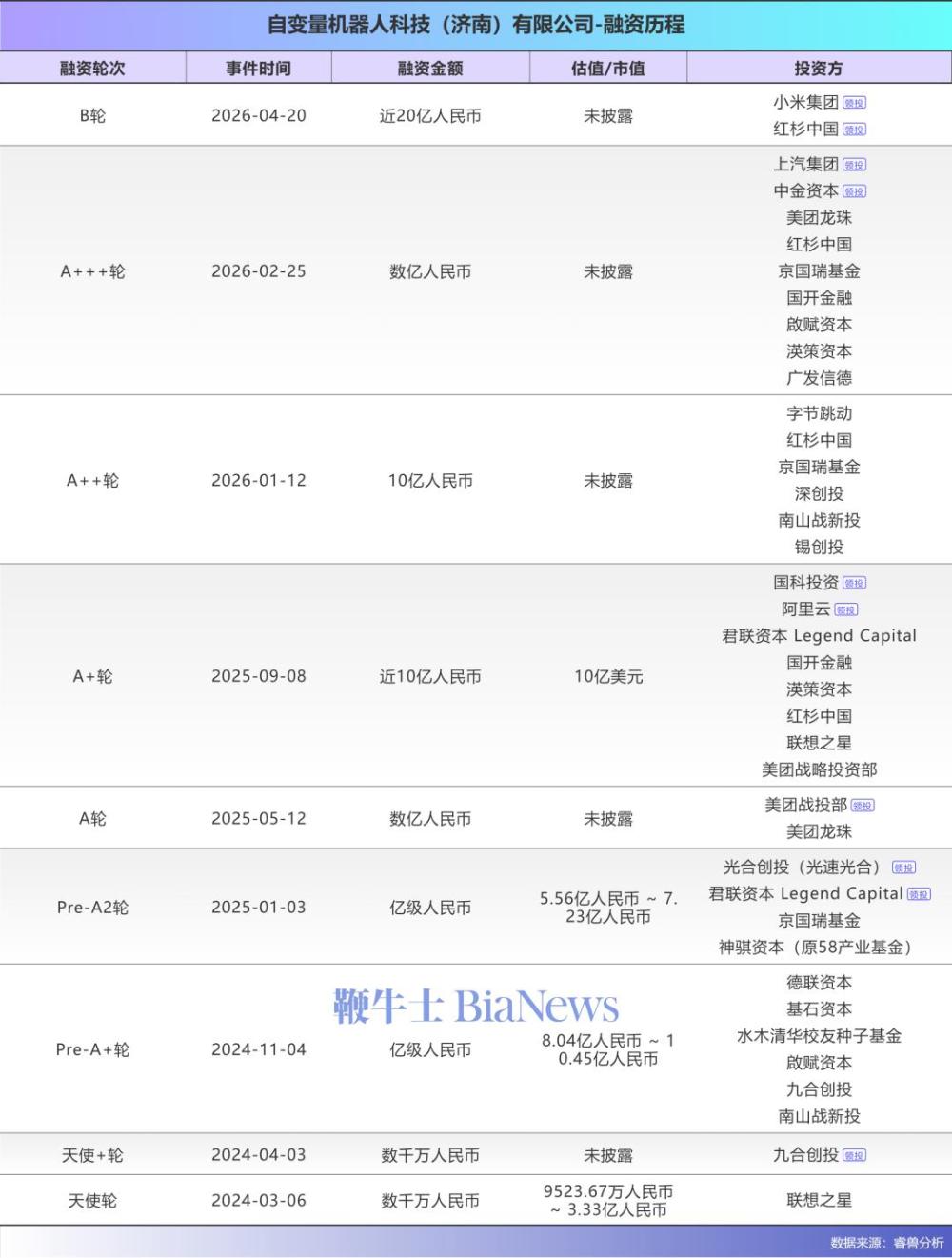
4月20日,具身智能赛道一笔近20亿元的融资宣告落地——自变量机器人宣布完成B轮融资,由小米战投与红杉中国联合领投,至此,集齐了字节跳动、阿里巴巴、美团、小米、联想、上汽、58同城等产业龙头的战略投资。目前,自变量累计融资超40亿,估值超100亿,而能和它在大脑和真机数据抗衡的,只有星海图、千寻、智元和宇树了。融资消息公布的第二天,这家由85后技术大佬王潜创办的公司,便开了发布会,宣布推出全球首个基于世界统一模型架构(WUM)的具身智能基础模型WALL-B,同时抛出了行业内迄今为止最明确的家庭落地计划:“35天后(即2026年5月25日),搭载WALL-B的新一代机器人将正式入驻首批真实家庭。”看起来,目前自变量先把自己战略先聚焦在最难最远的家庭机器人场景。业界公认的是,工厂是机器人最先进入的场景。而家庭是终极考场,也是最远的场景,机器人进入家庭至少还需10年以上的时间,但也是99%的机器人都跨不过去的门槛。然后再进入工业场景。王潜在现场也戳破了行业的“表演式创新”泡沫:目前全球没有任何一台机器人,能在无遥控、无预编程的情况下,独立完成家庭场景里的综合整理任务。”自变量的这次落地,是国内具身智能行业第一次把通用家庭服务机器人,从实验室的PPT和Demo,推向了普通用户的真实家庭,进行科普和用户教育,更重要的是数据采集。虽然投入采集数据成本巨大,可能对于企业而言,用钱拿数据,差异化专注单一最大市场,迅速占领用户心智可能更重要,以及最短时间实现资本价值,才是王道。面对行业长期的技术瓶颈,自变量给出的解决方案,是彻底推翻了当前行业主流的VLA(视觉-语言-动作)架构,用全新的WUM世界统一模型重构了机器人的“智能大脑”。王昊解释:“VLA本质上是视觉、语言、动作三个独立模块的拼接,数据在三个模块里逐级传递,每过一次模块边界,就会发生信息损耗和延迟。视觉模块学到的丰富信息,传到动作模块时,只剩一个模糊的摘要。”更根本的问题是,它只能模仿训练数据里的轨迹,根本不理解物理世界的规律,它不知道杯子为什么会掉,不知道盘子悬在桌边会摔碎,只是在重复见过的东西。而最新的WALL-B,其核心的WUM世界统一模型,设计逻辑类比苹果M1芯片的统一内存架构,把视觉、语言、动作、物理预测等所有能力,放在同一个网络中从零开始联合训练,彻底消除模块间的边界和数据搬运损耗,实现了从“拼接式架构”到“原生统一整体”的跨越。王潜直言不讳地表达了对行业主流路线的判断:“现在行业里要么是从VLM大模型延伸到VLA,要么是从视频生成/世界模型延伸到动作模块,这两种做法本质上都有问题。这些模型本来就不是为具身智能、为物理世界交互训练的,根本捕捉不到我们真正关心的核心规律。”“我们做的,是专门为机器人、为物理世界打造的基础模型,彻底从头开始预训练,这和行业主流路线是完全相反的。”基于WUM架构,WALL-B形成了三个区别于行业现有方案的核心特征:第一是原生多模态融合,首次实现“原生本体感”,无需持续观察自身、无需依赖大量外部传感器,就能内在感知自身的空间尺寸与动作边界,王昊补充说“这种内生的空间感知能力,甚至很多动物都不具备”;第二是掌握物理世界底层规律,能基于重力、惯性、摩擦力等通用物理规则预判风险,实现跨场景零样本泛化,无需针对每个家庭重新训练;第三是可自主交互、自我进化,任务失败后会自主调整策略重试,成功后直接将经验更新到模型参数中,无需工程师重训、无需返回实验室,王昊强调“它没有固定的迭代周期,执行任务的同时就在回流数据,模型进化、数据回流、效果评估在同一时刻发生,这和行业传统的离线训练模式有本质区别”。自变量采用了WUM架构作为技术底座,同时宣布自己用的是真实家庭场景的“牛奶数据”, 以此作为自己壁垒。王昊认为,“行业里大多数模型用的都是实验室的‘糖水数据’,干净、可控、量大,但和真实世界完全脱节。”他直言,实验室里固定的光照、固定的物品摆放、无干扰的环境,和家庭里随时变化的自然光、随意堆放的物品、孩子和宠物的随机动作完全是两回事,“用糖水数据训出来的模型,在实验室里表现再好,到了真实家庭里立刻就失效了”。而自变量从成立之初就坚定选择了“牛奶数据”的路线——真实家庭环境中采集的嘈杂、多变、充满随机性的数据。王潜提到,为了获取这类数据,团队深入了数百个志愿者的真实家庭,每一户的户型布局、灯光条件、物品摆放、生活习惯都完全不同,有的家庭地面散落着玩具和快递箱,有的家庭猫会突然跳上操作台面,有的家庭厨房和客厅冷暖光差异极大,“这些变量在实验室里根本无法1:1模拟,但却是家庭环境里的日常,也是模型必须学会应对的真实条件”。这种方式和美国机器人大脑的头部公司Physical Intelligence的数据采集方法基本一致。王昊拆解了自变量的数据分级体系,以及不同类型数据的价值差异。“我们核心坚持数据必须来自真实环境,同时把真实世界的数据做了明确分级,从最底层的本体操作数据,到穿戴设备采集的视频数据,再到最高价值的交互式数据。”他解释,所谓交互式数据,不是人工远程操作机器人采集的固定数据,而是让机器人自主探索、人机协作过程中产生的数据,“看起来越容易获取的纯视频数据,训练难度反而越大,信息密度越低;而交互式数据的物理信息最丰富,价值最高,虽然采集难度最大,却是我们最核心的数据源”。王昊反复强调,数据的价值从来不是以条数衡量的,而是以它能覆盖的任务丰富度、复杂程度来衡量的。“我们不会为了某个任务刻意采集固定条数的数据,更不会预设机器人要做多少次才能学会一件事。我们的逻辑是先让搭载模型的机器人去真实场景里做,能做的部分自主完成,做不好的部分人工辅助,这个过程中产生的数据,才是真正有价值的。”此前,自变量基于上一代WALL-AS模型,已经通过与58同城的合作,跑通了“商业落地-数据回流-模型迭代”的正向飞轮,这也是其敢在35天后推进家庭入驻的核心前提。王潜介绍,和58的合作不是Demo测试,而是真实的付费商业服务:“深圳的用户现在打开58 APP,就能直接约机器人上门服务,机器人和保洁阿姨一起进家,现场不需要我们的员工实时支持,只在遇到无法处理的问题时,触发远程人工接管兜底,解决问题后再交还给AI自主执行。”而35天后,搭载WALL-B新模型的机器人入驻家庭,就如同和“住家阿姨”一样。针对35天后即将开始的机器人开始入驻家庭场景的最核心的隐私顾虑,自变量也同步明确了三大解决方案:
首先,设备端实时视觉脱敏,原始图像不离开设备;
其次,用户主动授权才能开机,无任何“默认同意”;
最后,数据绝不共享第三方,机器人只认一个主人,发现可疑指令立即锁定。
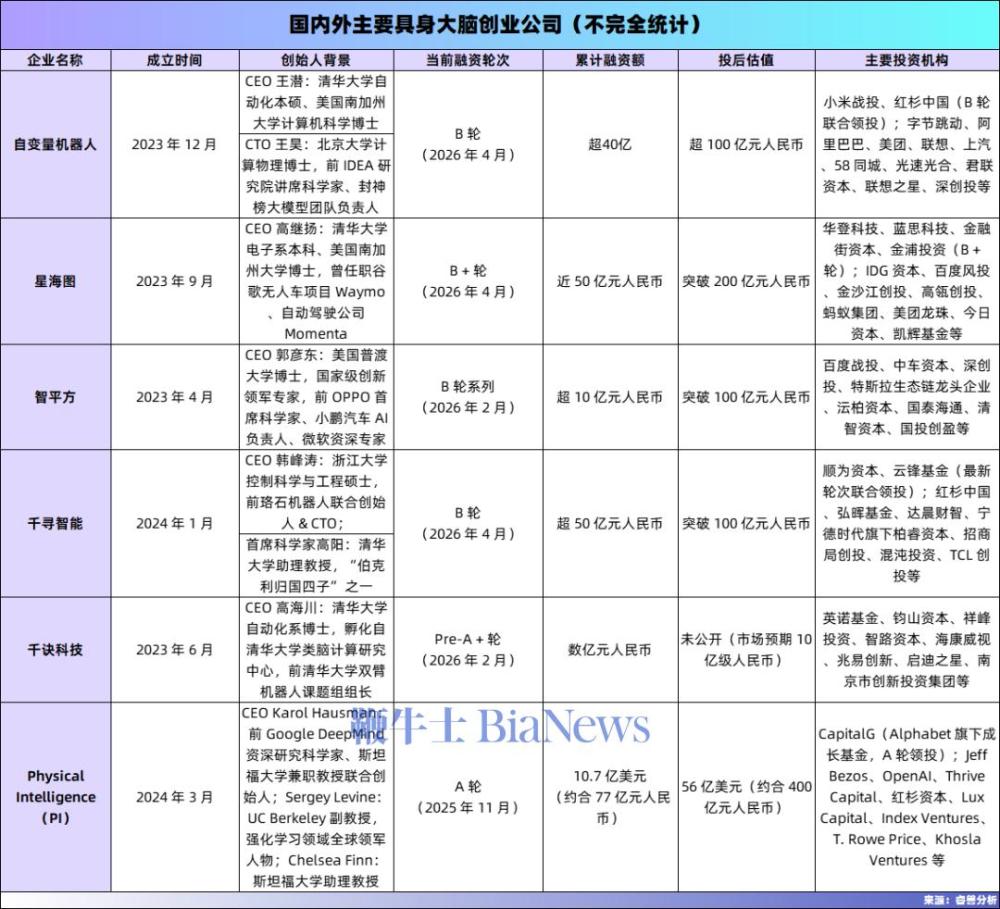
王昊表示,自变量的模型迭代逻辑和行业完全不同:“传统模式是先有数据,再训模型,再去新场景评测;我们是大规模预训练后,模型已经具备零样本泛化基础,直接让机器人去真实家庭里执行任务,做不了的部分通过人机协作完成,数据同步回流,下一次就能克服这个困难,全程不需要刻意采集数据。”  对于数据配比与数采工厂的布局,王潜介绍:“我们2024年初就建成了自有的数据采集工厂,目前仍是全国乃至全球规模最大的数采工厂之一。我们会平等对待工厂采集的数据和真实家庭场景的数据,把它们当成一个统一的集合调整配比,不会做生硬的切割。整体数据策略就是‘实验数据打底,真实场景提质’,实验室数据用来建立基础的物体识别、动作执行能力,真实家庭数据用来让模型学会在不确定环境中生存。”本轮融资完成后,自变量已经成为国内具身智能赛道里,唯一一家集齐字节跳动、阿里巴巴、美团、小米四大互联网巨头战略投资的企业,股东名单还包括联想、上汽、58同城等产业龙头,可以说是赛道内集齐产业投资方最多的创业公司。一个无法回避的问题是:小米、阿里、字节、美团这些巨头,自身都已布局具身智能赛道,拥有独立的机器人研发团队,为什么还要集体投资自变量?王潜直接回应了这个问题:“我们算是整个中国AI领域,不光具身领域,大厂投的最多的一家公司,所有投我们的大厂,自己都在做具身,这也不妨碍他们投我们。核心原因有两个,第一,这个市场足够巨大,容得下多家玩家;第二,创业公司在这件事上,有大厂完全比不了的优势。”在他看来,产业资方集体押注自变量,核心看中的是其不可复制的技术壁垒与全链路能力,这也是自变量区别于其他模型创业公司、甚至大厂内部团队的核心优势。当前行业内绝大多数玩家,包括大厂的很多团队,走的都是“基于开源大模型微调,拼接视觉、动作模块”的捷径,而自变量是国内极少数坚持从头自研具身智能基础模型的企业,其WUM架构的路线,与行业主流VLA路线形成了明显的差异化,也构建了更高的技术门槛。“模型架构很容易抄,半年时间,大家就能搞明白上一代模型的架构。但抄不走的,是从数据定义、采集、清洗、过滤,到训练、评测、迭代的全链路工程体系。”王潜以OpenAI举例,“OpenAI领先了谷歌两年,在机器人领域,这个技术领先的窗口期会更长,至少三年以上。”更关键的是,大模型可以通过蒸馏降低技术门槛,但机器人不行。“为什么大家觉得大模型时代技术门槛变低了?因为蒸馏做得太多了,大家都忘了真正的技术差距是什么。但机器人这个东西,没法蒸馏。”这是王潜反复强调的核心竞争优势,自变量不仅做模型算法,还实现了机器人本体、机械臂、力控关节、主控制器等核心零部件的全面自研,能从模型需求出发定义硬件,从硬件特性优化模型,实现软硬深度适配。而大厂的组织架构里,硬件团队和算法团队往往是分开的,很难实现这种全链路的拉通与协同。除了技术本身,产业投资方与自变量的业务协同,也是投资的核心逻辑。例如,与58同城、美团的协同,是家庭服务与本地生活场景的深度绑定,二者的海量家庭订单与线下资源,既可以成为自变量真实数据的核心来源,也是未来规模化落地的核心渠道。随着巨头下场、创业公司扎堆,具身智能赛道的竞争早已进入白热化阶段,而在核心的具身智能大脑赛道,国内外玩家的路线分化已经愈发明显。国内市场,除了自变量之外,星海图、智平方、千寻智能、千诀科技是赛道内的核心竞争者,各家路线差异显著。其中,星海图同样聚焦通用具身大模型研发,侧重多模态交互与机器人操控的端到端落地;智平方则以工业场景为核心切口,基于VLA架构打磨垂直场景的具身模型,优先落地工厂产线的标准化作业;千寻智能深耕VLA架构的轻量化落地,主打消费级机器人的智能升级;千诀科技则采用类脑分区架构,主打解耦、跨硬件适配、超长时自主决策,定位 “机器人的智能操作系统”。海外市场,自变量的核心对标企业是Physical Intelligence(PI),这家企业同样聚焦通用具身智能基础模型研发,主打基于大模型的机器人通用操控能力,获得了微软、英伟达等企业的投资。在王潜看来,当前的具身智能赛道,已经分化成了两条完全不同的发展路线:一条是硬件优先路线,以双足人形机器人为核心,主打舞台表演、工业巡检、封闭场景作业,核心竞争点是硬件性能、运动控制能力;另一条是智能优先路线,以通用具身基础模型为核心,主打开放场景的通用交互与操作,核心竞争点是模型的泛化能力、物理世界理解能力、自主进化能力。“跑马拉松的双足机器人,和我们做的事,是两个完全不同的领域,甚至两个完全不同的行业。”王潜认为,“硬件在中国从来都没有壁垒——今天你做出来一个特别好的硬件,明天供应链就全给你整明白了,后天所有人都能做一模一样的东西。硬件的壁垒,只能靠产品、商务去构建,但我们做的,是基础模型的事,壁垒要高得多得多。”而关于两条路线的底层逻辑差异,王潜进一步解释:“工业和家庭是两个极端相反的场景,家庭是极致开放的场景,对泛化性、复杂度的要求到了极致,核心靠预训练的基础模型;工业是相对封闭的场景,对速度、准确率的要求极高,核心靠后训练的场景优化,技术上是两个完全不同的方向。”自变量的战略是先家庭,后工业。他反复强调,舞台上机器人的后空翻、跳街舞,视觉冲击力再强,本质也都是预设轨迹的“命令行机器人”;工厂里的工业机器人可以把一个动作重复一万次,每次环境条件完全一致,但家庭场景完全相反:一万个动作每个可能只做一次,每次的环境条件都不一样。这种极致的随机性、碎片化,以及上肢精细操作中无处不在的非线性物理交互,让家庭场景成为对机器人智能能力的终极考验,也让行业长期陷入“双足、灵巧手、力控关节等硬件早已到位,大脑却没跟上”的困局。而自变量的逻辑是,先把基础模型的底座打牢,再去拓展工业等垂直场景,而不是反过来。对于行业未来的发展,王潜的判断是:未来两到三年,具身智能行业就会迎来物理世界的“Aha moment”,就像当年ChatGPT引爆数字世界一样。
对于数据配比与数采工厂的布局,王潜介绍:“我们2024年初就建成了自有的数据采集工厂,目前仍是全国乃至全球规模最大的数采工厂之一。我们会平等对待工厂采集的数据和真实家庭场景的数据,把它们当成一个统一的集合调整配比,不会做生硬的切割。整体数据策略就是‘实验数据打底,真实场景提质’,实验室数据用来建立基础的物体识别、动作执行能力,真实家庭数据用来让模型学会在不确定环境中生存。”本轮融资完成后,自变量已经成为国内具身智能赛道里,唯一一家集齐字节跳动、阿里巴巴、美团、小米四大互联网巨头战略投资的企业,股东名单还包括联想、上汽、58同城等产业龙头,可以说是赛道内集齐产业投资方最多的创业公司。一个无法回避的问题是:小米、阿里、字节、美团这些巨头,自身都已布局具身智能赛道,拥有独立的机器人研发团队,为什么还要集体投资自变量?王潜直接回应了这个问题:“我们算是整个中国AI领域,不光具身领域,大厂投的最多的一家公司,所有投我们的大厂,自己都在做具身,这也不妨碍他们投我们。核心原因有两个,第一,这个市场足够巨大,容得下多家玩家;第二,创业公司在这件事上,有大厂完全比不了的优势。”在他看来,产业资方集体押注自变量,核心看中的是其不可复制的技术壁垒与全链路能力,这也是自变量区别于其他模型创业公司、甚至大厂内部团队的核心优势。当前行业内绝大多数玩家,包括大厂的很多团队,走的都是“基于开源大模型微调,拼接视觉、动作模块”的捷径,而自变量是国内极少数坚持从头自研具身智能基础模型的企业,其WUM架构的路线,与行业主流VLA路线形成了明显的差异化,也构建了更高的技术门槛。“模型架构很容易抄,半年时间,大家就能搞明白上一代模型的架构。但抄不走的,是从数据定义、采集、清洗、过滤,到训练、评测、迭代的全链路工程体系。”王潜以OpenAI举例,“OpenAI领先了谷歌两年,在机器人领域,这个技术领先的窗口期会更长,至少三年以上。”更关键的是,大模型可以通过蒸馏降低技术门槛,但机器人不行。“为什么大家觉得大模型时代技术门槛变低了?因为蒸馏做得太多了,大家都忘了真正的技术差距是什么。但机器人这个东西,没法蒸馏。”这是王潜反复强调的核心竞争优势,自变量不仅做模型算法,还实现了机器人本体、机械臂、力控关节、主控制器等核心零部件的全面自研,能从模型需求出发定义硬件,从硬件特性优化模型,实现软硬深度适配。而大厂的组织架构里,硬件团队和算法团队往往是分开的,很难实现这种全链路的拉通与协同。除了技术本身,产业投资方与自变量的业务协同,也是投资的核心逻辑。例如,与58同城、美团的协同,是家庭服务与本地生活场景的深度绑定,二者的海量家庭订单与线下资源,既可以成为自变量真实数据的核心来源,也是未来规模化落地的核心渠道。随着巨头下场、创业公司扎堆,具身智能赛道的竞争早已进入白热化阶段,而在核心的具身智能大脑赛道,国内外玩家的路线分化已经愈发明显。国内市场,除了自变量之外,星海图、智平方、千寻智能、千诀科技是赛道内的核心竞争者,各家路线差异显著。其中,星海图同样聚焦通用具身大模型研发,侧重多模态交互与机器人操控的端到端落地;智平方则以工业场景为核心切口,基于VLA架构打磨垂直场景的具身模型,优先落地工厂产线的标准化作业;千寻智能深耕VLA架构的轻量化落地,主打消费级机器人的智能升级;千诀科技则采用类脑分区架构,主打解耦、跨硬件适配、超长时自主决策,定位 “机器人的智能操作系统”。海外市场,自变量的核心对标企业是Physical Intelligence(PI),这家企业同样聚焦通用具身智能基础模型研发,主打基于大模型的机器人通用操控能力,获得了微软、英伟达等企业的投资。在王潜看来,当前的具身智能赛道,已经分化成了两条完全不同的发展路线:一条是硬件优先路线,以双足人形机器人为核心,主打舞台表演、工业巡检、封闭场景作业,核心竞争点是硬件性能、运动控制能力;另一条是智能优先路线,以通用具身基础模型为核心,主打开放场景的通用交互与操作,核心竞争点是模型的泛化能力、物理世界理解能力、自主进化能力。“跑马拉松的双足机器人,和我们做的事,是两个完全不同的领域,甚至两个完全不同的行业。”王潜认为,“硬件在中国从来都没有壁垒——今天你做出来一个特别好的硬件,明天供应链就全给你整明白了,后天所有人都能做一模一样的东西。硬件的壁垒,只能靠产品、商务去构建,但我们做的,是基础模型的事,壁垒要高得多得多。”而关于两条路线的底层逻辑差异,王潜进一步解释:“工业和家庭是两个极端相反的场景,家庭是极致开放的场景,对泛化性、复杂度的要求到了极致,核心靠预训练的基础模型;工业是相对封闭的场景,对速度、准确率的要求极高,核心靠后训练的场景优化,技术上是两个完全不同的方向。”自变量的战略是先家庭,后工业。他反复强调,舞台上机器人的后空翻、跳街舞,视觉冲击力再强,本质也都是预设轨迹的“命令行机器人”;工厂里的工业机器人可以把一个动作重复一万次,每次环境条件完全一致,但家庭场景完全相反:一万个动作每个可能只做一次,每次的环境条件都不一样。这种极致的随机性、碎片化,以及上肢精细操作中无处不在的非线性物理交互,让家庭场景成为对机器人智能能力的终极考验,也让行业长期陷入“双足、灵巧手、力控关节等硬件早已到位,大脑却没跟上”的困局。而自变量的逻辑是,先把基础模型的底座打牢,再去拓展工业等垂直场景,而不是反过来。对于行业未来的发展,王潜的判断是:未来两到三年,具身智能行业就会迎来物理世界的“Aha moment”,就像当年ChatGPT引爆数字世界一样。


 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握


 微信好友
微信好友
 朋友圈
朋友圈
 鞭牛士公众号
鞭牛士公众号
 鞭牛士微博
鞭牛士微博