

3月19日消息,今日凌晨,小米MiMo大模型系列重磅三连更:旗舰基座大模型MiMo-V2-Pro、全模态Agent模型MiMo-V2-Omni、MiMo-V2-TTS,其最新发布的这三大模型都是为优化智能体能力打造。
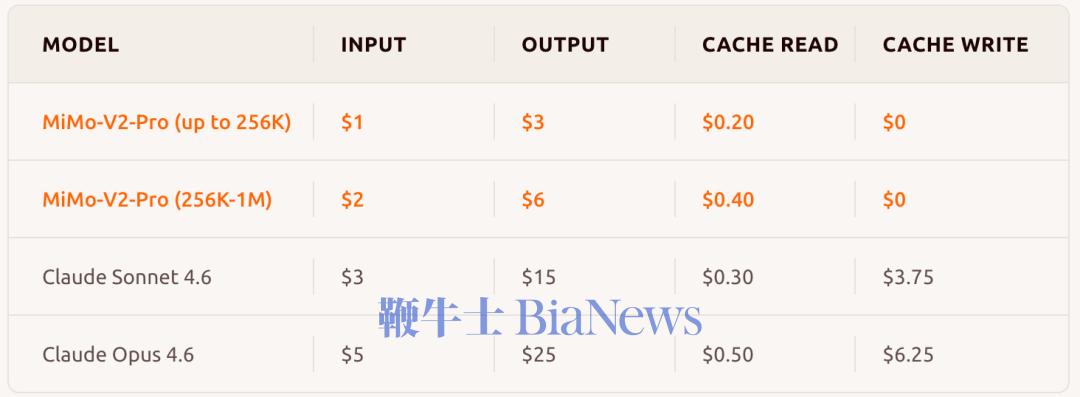
▲MiMo-V2-Pro与Claude Opus 4.6、Claude Sonnet 4.6价格对比(图源:小米MiMo官网)
全模态基座模型Xiaomi MiMo-V2-Omni,支持文本、视觉、语音全模态,该模型能够跨模态理解复杂环境、自主制定并执行计划、在遇到异常时实时修正策略,最终端到端地交付完整结果。 语音合成大模型Xiaomi MiMo-V2-TTS要让智能体能用有温度、有情感、有灵魂的声音与人对话,其支持多方言、多角色、多语气生成,还可以智能识别文本中的标点符号、语气词、强调标记等各类格式信号。 智东西体验了MiMo Claw,让其“帮我设计一个网站,每天19点更新第二天在港交所、A股上市的企业”。MiMo Claw通过Python爬虫定时抓取数据,然后生成静态页面直接部署。其运行测试发现误匹配后,会修正补充港股数据。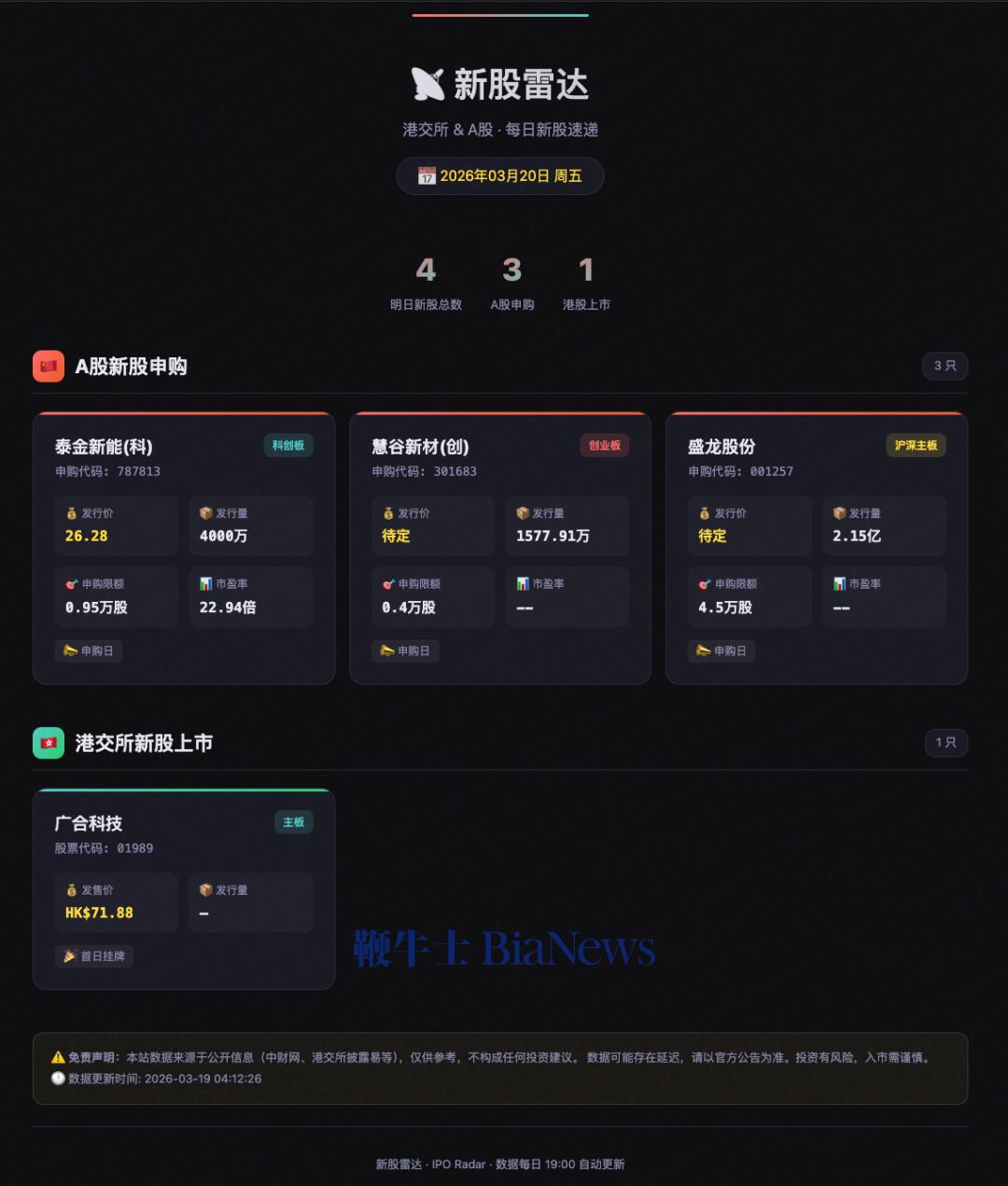
▲MiMo Claw生成的新股雷达网站
MiMo-V2-Pro、MiMo-V2-Omni将联合OpenClaw、OpenCode、KiloCode、Blackbox及Cline等智能体开发框架团队,为全球开发者提供为期一周的限时免费接口支持。
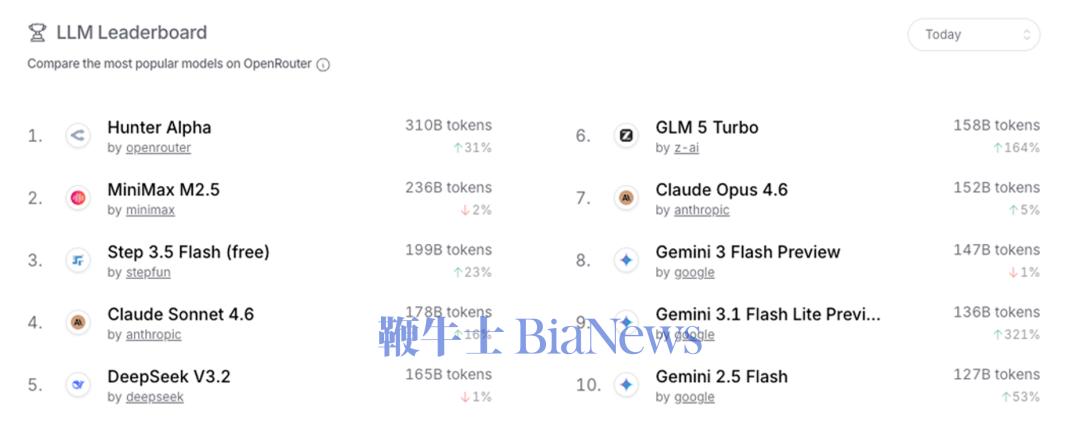
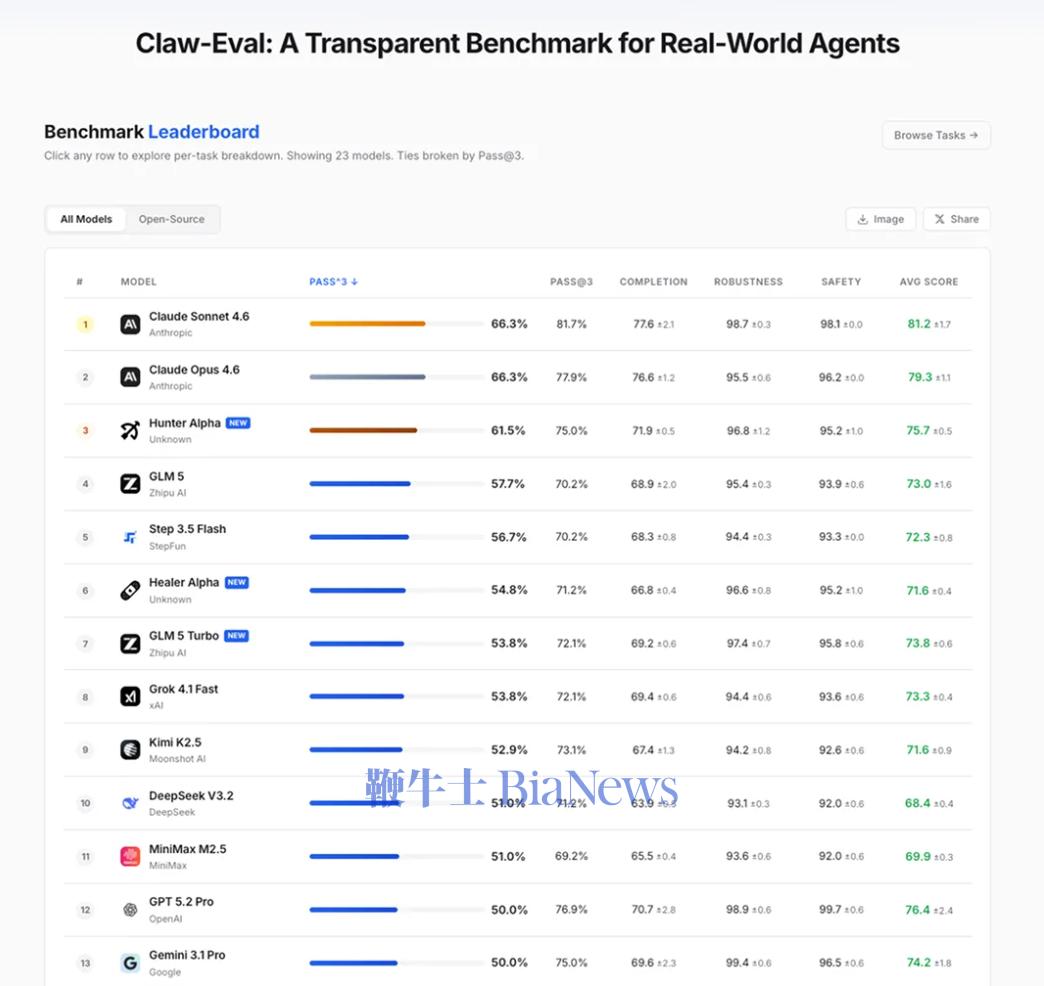
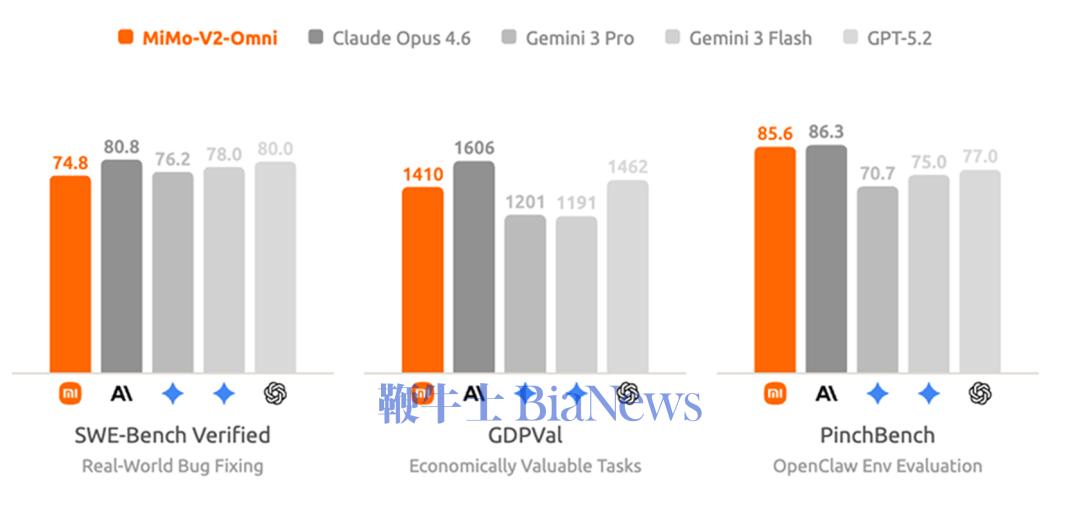
MiMo-V2-Pro总参数量超过1T,激活参数量42B,较前代模型MiMo-V2-Flash扩大约3倍,支持100万上下文长度。 在全球权威大模型综合智能排行榜Artificial Analysis上,MiMo-V2-Pro位列全球第九,国内第三,仅次于智谱的GLM-5、MiniMax昨日新发布的MiniMax-M2.7。 在各个衡量模型重要能力的基准测评中,MiMo-V2-Pro在编程Agent、通用Agent和工具使用方面与Claude Sonnet 4.6、GPT 5.2、Gemini 3.0 Pro性能相近。 根据官方信息,MiMo-V2-Pro专为Agent场景深度优化,针对复杂多样的智能体架构进行了监督微调和强化学习,具备更强工具调用与多步推理能力。 在OpenClaw标准评测榜单PinchBench、Claw-Eval上,MiMo-V2-Pro排名第三,仅次于Claude Sonnet 4.6、Claude Opus 4.6。同时,基于1M超长上下文窗口,MiMo-V2-Pro能支撑高强度的真实Claw复杂应用流。 编程方面,小米内部工程师深度评测结果显示,MiMo-V2-Pro体感已接近Claude Opus 4.6,并展现出高阶的编程智能,其拥有更出色的系统设计与任务规划能力、更优雅的代码风格,以及更高效直接的问题解决路径。 在前端应用场景中,MiMo-V2-Pro可以在OpenClaw里,一步生成设计精致、功能完备的网页。 提示词:模仿90年代印刷杂志美学。标题衬线字体如 Playfair Display,正文等宽字体如 IBM Plex Mono。页面杂志式多栏 grid,每栏宽度不等。大标题向左偏出视口暗示印刷溢出。图片加 sepia 0.2 棕褐色滤镜和噪点叠加。页面过渡模仿翻书效果。导航模仿杂志目录,每项前编号 01/02/03,hover 时编号变大。底部设计成杂志版权页样式含假 ISSN 号。纸张纹理背景。 价格方面,根据使用量分段计价:256K上下文以内,输入每百万tokens 1美元(约合人民币6.87元),输出3美元(约合人民币20.62元);1M上下文以内,输入每百万tokens 2美元(约合人民币13.75元),输出6美元(约合人民币41.24元)。 在官方模型体验页面,同步上线了MiMo Claw,免费解锁MiMo-V2-Pro养虾体验。此外,MiMo Claw模块现已全面打通金山WebOffice生态,原生支持Word、Excel、PPT、PDF四大主流格式,覆盖超95%的日常文档类型;小米浏览器目前也已经接入MiMo-V2-Pro,助力AI搜索。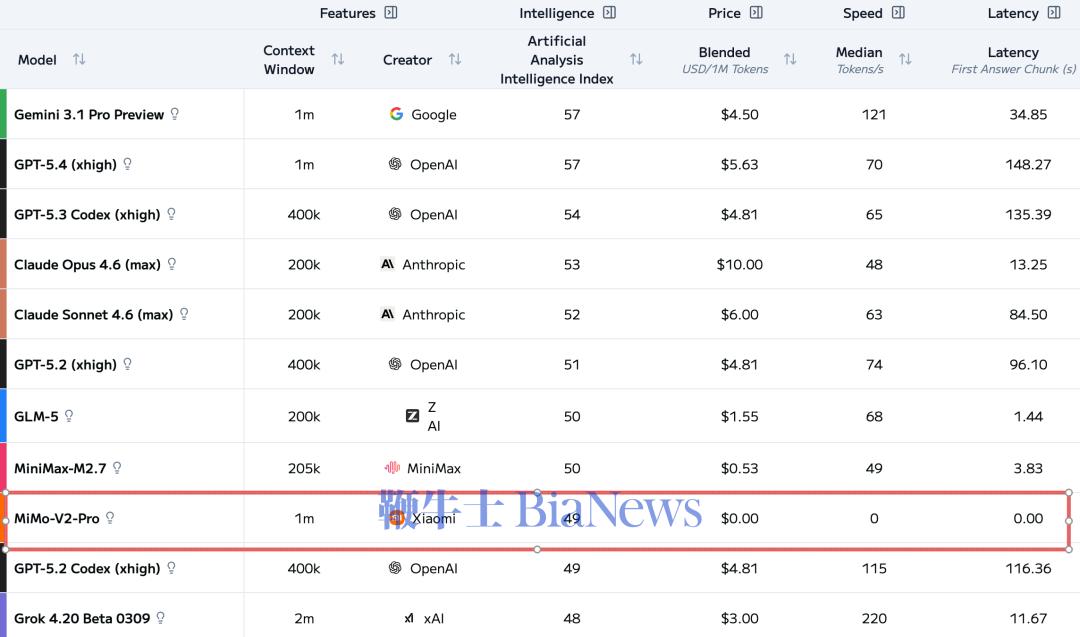
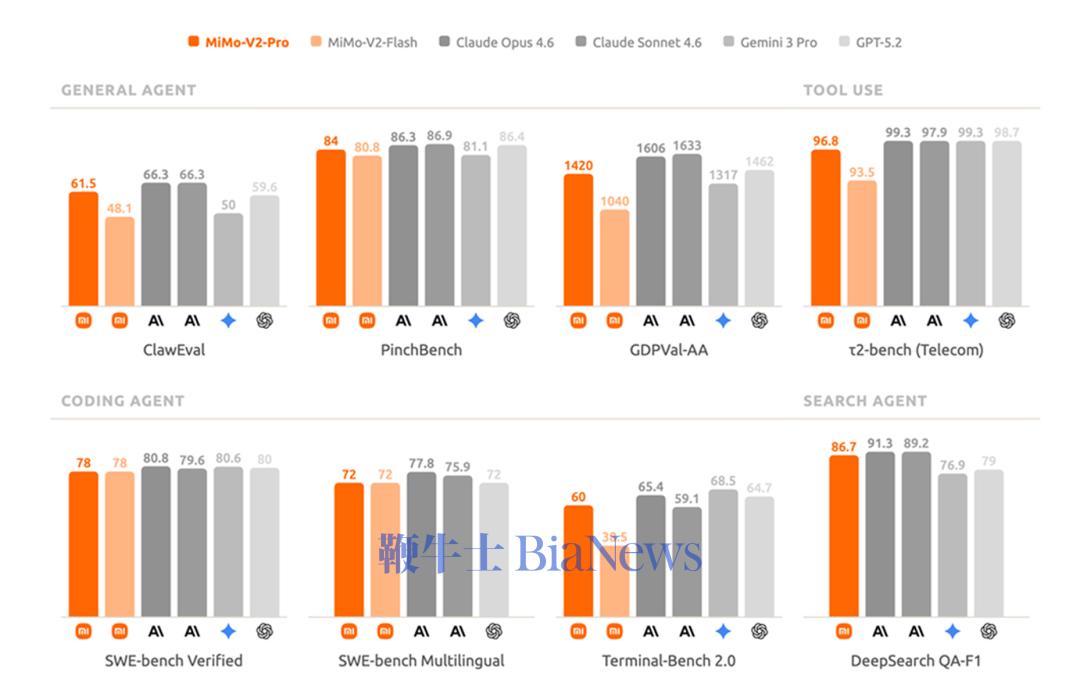

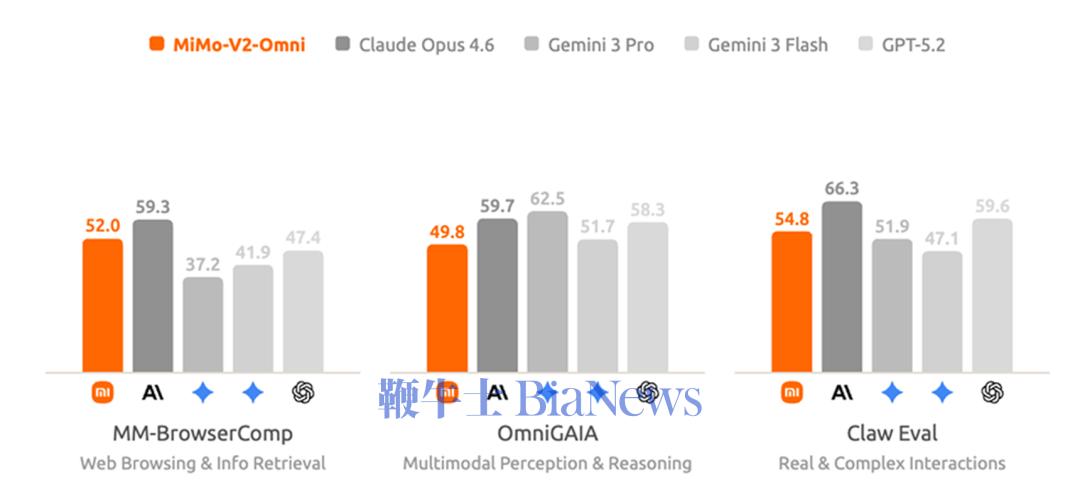
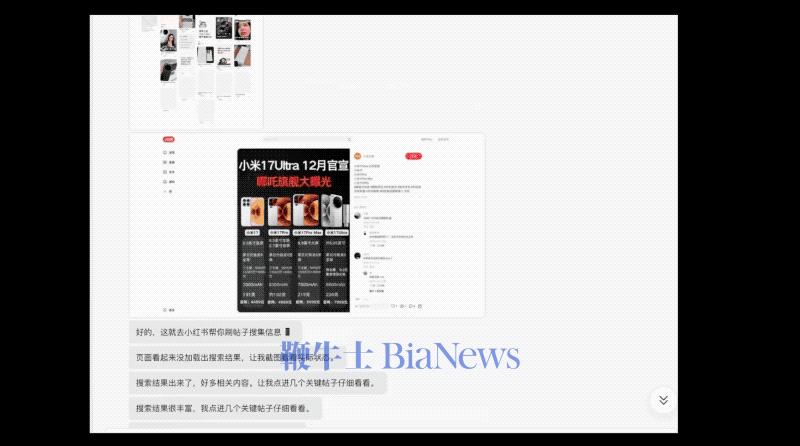
全模态基座模型Xiaomi MiMo-V2-Omni,是专为现实世界中复杂的多模态交互与执行场景打造,融合文本、视觉、语音全模态。 感知能力,精准感知和准确推理是高效执行的基石。在音频理解上,MiMo-V2-Omni支持从环境声分类、多说话人分离、音频-视觉联合推理、超过10小时连续长音频的深度理解。其表现超越了Gemini 3 Pro;图像理解上,MiMo-V2-Omni具备多学科视觉推理与复杂图表分析能力,其表现超过Claude Opus 4.6,逼近Gemini 3 Pro;视频理解方面,新模型支持原生音视频联合输入,表现超越Gemini 3 Flash。 智能体能力方面,MiMo-V2-Omni能够跨模态理解复杂环境、自主制定并执行计划、在遇到异常时实时修正策略,最终端到端地交付完整结果。 在与真实数字环境交互的评测基准上,MiMo-V2-Omni性能逼近Gemini 3 Pro,纯文本智能体任务上,其平均表现仅次于Claude Opus 4.6。 结合OpenClaw框架,MiMo-V2-Omni可以像人一样操控浏览器。 提示词:帮我看看小米17怎么选,去小红书做做功课,选好了去京东下单,顺便砍砍价。 模型会自己打开小红书翻帖子,提取配置对比、拍照评测、真实用户体验然后整理购买建议。然后其会打开京东跨店比价,转接人工客服砍价,价格合适后直接加购下单。 MiMo-V2-Omni接入WPS Office,只需几句话就可以为用户直接生成Word、结构化Excel、排版规范的PDF与完整的PPT。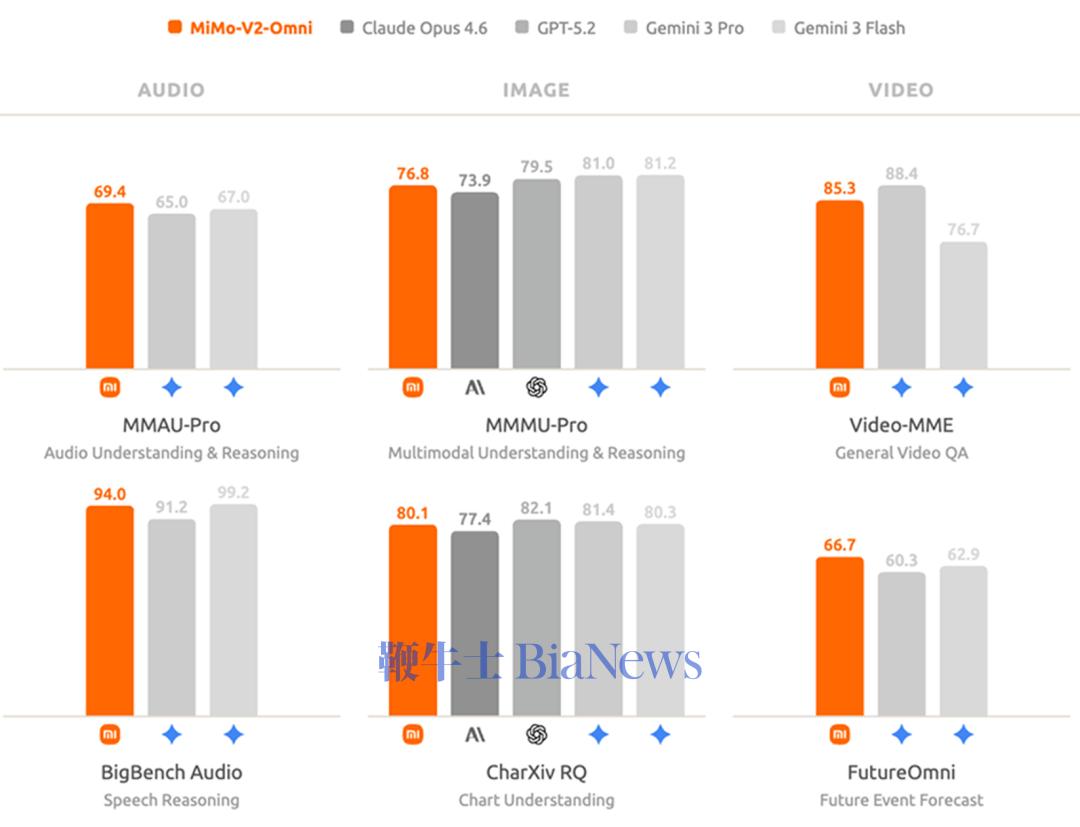

语音合成大模型Xiaomi MiMo-V2-TTS,专为Agent时代的全模态交互而生,让智能体能用有温度、有情感、有灵魂的声音与人对话。 该模型基于小米自研Audio Tokenizer和多码本语音-文本联合建模架构,经过上亿小时语音数据的大规模预训练与多维度强化学习,实现了高度可控的多粒度语音风格控制。 其中,自研多码本语音建模架构,可以实现更精细的语音特征捕捉与还原,模型在高保真的离散token空间中对语音进行建模,保留原始语音中的丰富信息,使强化学习阶段能够直接利用语音相关奖励信号对模型进行优化,从而让多维奖励信号更有效。 语音数据量突破上亿小时,覆盖丰富的说话风格与场景;多维度强化学习后训练中,MiMo-V2-TTS在能围绕更自然的韵律、更稳定的音质、更准确的字词表达、更高质量的音色克隆以及不同场景下恰当的语气和表达方式等多个维度持续优化。 在训练过程中,MiMo-V2-TTS首先通过超大规模语音-文本混合预训练,在海量数据中习得了强大的跨模态对齐与理解生成的统一能力;在此基础上,通过少量高质量监督数据的微调,模型获得了可泛化的多粒度与多风格指令控制能力。 可泛化的语音风格指令控制:该模型支持从整体到局部的多层次语音风格控制。用户可通过自然语言指令设定整体语音基调,同时对句内局部片段进行细粒度的情绪调节,实现同一语句中语气转折与情感递变的自然过渡。 文本理解:该模型在预训练阶段通过大量文本-语音对齐数据,习得了书面语与口语表达之间的映射关系,能够智能识别文本中的标点符号、语气词、强调标记等各类格式信号,并将其自动转化为恰当、自然的语音表达,全程无需用户额外标注或手动干预。 方言、角色、歌声:该模型支持多种方言的自然发音,可进行角色扮演式的风格化演绎,更能实现高质量的歌声合成——让同一个模型既能说、能演、也能唱。方言支持:东北话、四川话、河南话、粤语、台湾腔。
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



