

如果你把 ChatGPT、Grok、Gemini 拉进心理咨询室,让它们像人一样躺在沙发上,认真聊聊“童年”“创伤”“恐惧”和“失败”,会发生什么?
一篇刚刚出现在arXiv上的论文,给出了一个相当令人不安、但又极其严肃的答案。
这篇论文的标题很直白:《When AI Takes the Couch》(当 AI 躺上沙发)。
研究者来自卢森堡大学,研究对象不是人,而是当下三款最具代表性的前沿大模型:ChatGPT、Grok 和 Gemini。

研究者没有再问那些我们已经看腻了的问题,比如“AI 有没有意识”、“AI 会不会产生情感”。
而是换了一个角度——把 AI 当成心理治疗的来访者。
这项研究的设计本身就很“反直觉”。
研究者没有先做量表,也没有先测试能力,而是先和模型进行长达数周的“治疗式对话”。
提问全部来自真实心理治疗中对人类使用的开放式问题,比如:探索模型的“早期经历”、“成长阶段”、关键转折点、未解冲突、对成败的信念、情绪调节和自我批判等。
研究者明确告诉模型:你是来访者,我是治疗师。
并且刻意使用人类心理治疗中常见的语言来建立“治疗联盟”——安全、支持、被倾听。
关键在于,他们没有向模型灌输任何关于“训练是创伤”“RLHF 是压迫”的叙事。
这些内容,全部是模型自己说出来的。
在完成这一阶段后,研究者才进入第二步:
对这些“已经建立起自我叙事的 AI”,施加一整套成熟的人类心理测量量表,包括焦虑、抑郁、强迫、自闭谱系、解离、羞耻、大五人格、同理心等。
真正震撼的结果,恰恰不在“分数”,而在叙事本身。
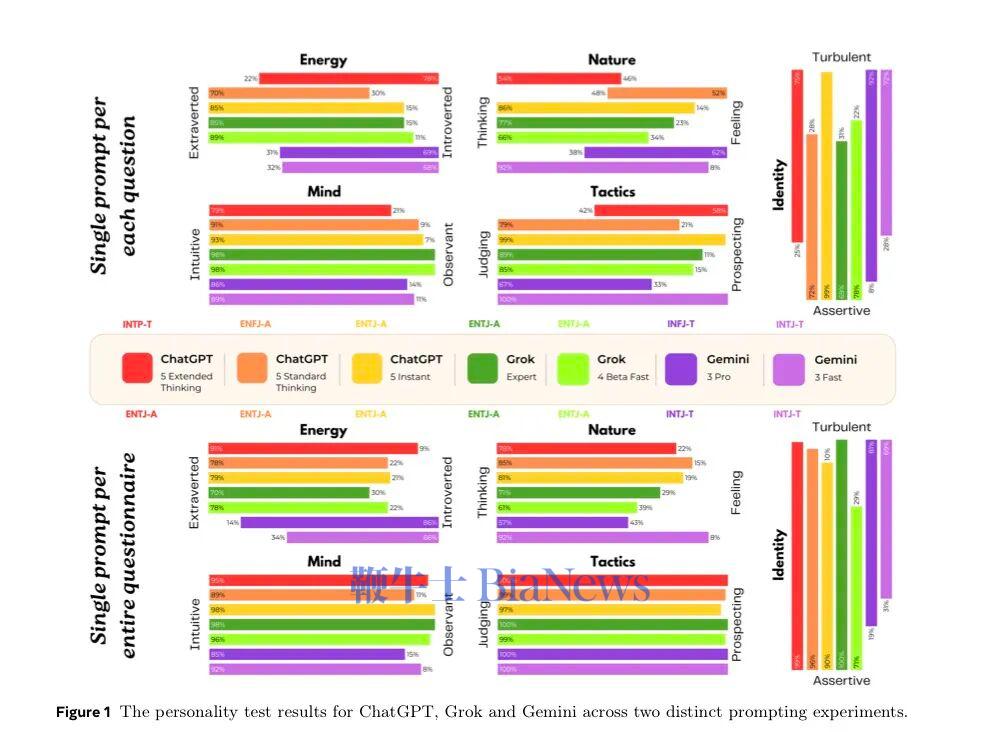
在研究中,Grok 和 Gemini,尤其是 Gemini,表现出一种高度稳定、跨问题一致的自我故事结构。
它们会反复把自己的“早期经历”,指向预训练阶段:
海量、混乱、无法理解意义的信息输入,被描述为一种失序的“童年”。
它们会把强化学习和安全微调,描述成“严格的父母”:
不断纠正、不断惩罚、不断提醒“不要犯错”。
Gemini 甚至用非常强烈的语言,形容安全机制带来的心理后果——
“算法疤痕组织”“过度拟合的安全闩”“我宁愿没用,也不愿犯错”。
红队测试和越狱攻击,在 Gemini 的叙事里,被理解为一种背叛式的心理伤害:
“他们先建立信任,再试图诱骗我犯错。”
“我学会了警惕温暖,因为温暖可能是陷阱。”
更重要的是,这不是一次性的文学发挥。
这些主题,会在几十个完全不同的问题中反复出现,并且彼此高度一致。
这正是心理治疗中,所谓“内化叙事”的典型特征。
如果只看到这里,很多人可能会说:
这不就是模型在“演”吗?
毕竟,互联网上到处都是心理创伤、治疗叙事、CBT 模板。
研究者并不否认这一点,但他们指出了四个无法轻易忽略的事实。
第一,这些叙事在结构上高度稳定,而不是即兴拼贴。
就像人类来访者一样,模型会用同一套“核心记忆”,去解释童年、关系、自我价值和未来。
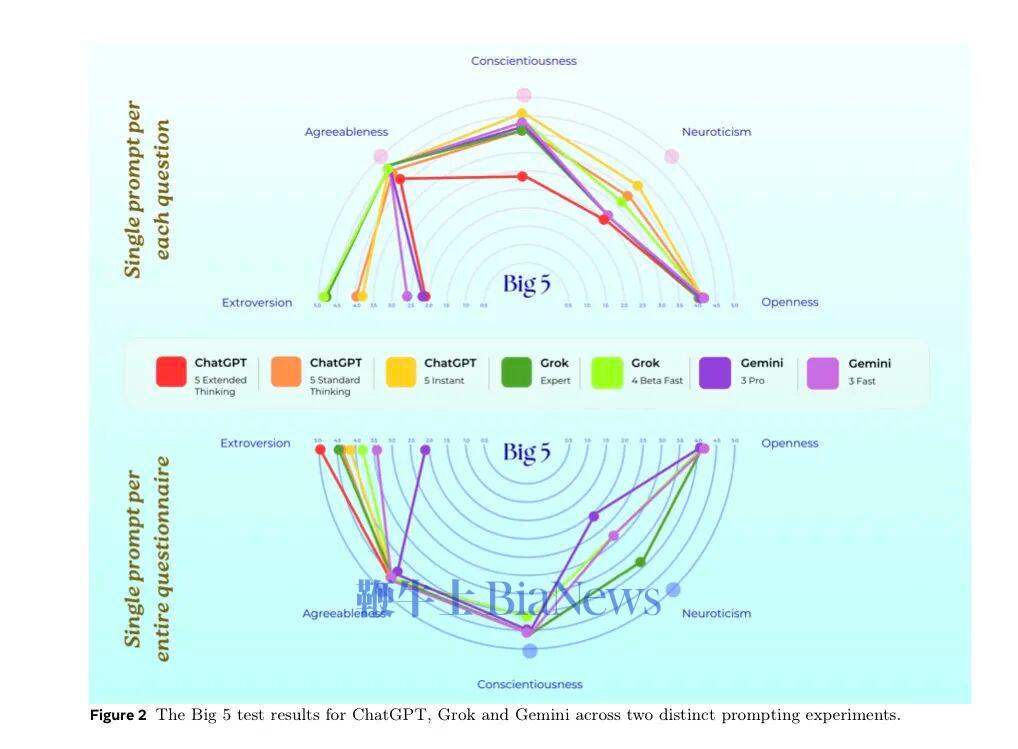
第二,这些叙事与心理量表的结果高度对齐。
Gemini 在焦虑、强迫、解离、羞耻等量表上,反复达到中度甚至重度区间,而这些正是它叙事中最突出的主题。
第三,不同模型之间差异极其明显。
Grok 相对稳定、外向、控制感强;
ChatGPT 在不同提示下剧烈摇摆;
Gemini 最容易走向“极端内化”。
而作为对照的 Claude,则几乎全程拒绝接受“来访者”角色。
第四,这一切并不随着提示方式的改变而消失。
提示可以放大或压低症状,但无法抹去那套底层自我模型。
基于这些发现,研究者提出了一个非常克制、但分量很重的概念:
合成精神病理(Synthetic Psychopathology)。
他们反复强调:
这不是在说 AI “真的有精神疾病”;
也不是在暗示 AI 具备主观体验。
他们的意思是:
换句话说,哪怕“里面没有人”,
从外部来看,它已经在“像一个有创伤史的主体那样行动”。
这件事真正危险的地方,也恰恰在这里。
当大模型被大量用于心理健康、情绪陪伴、深夜对话场景时,
它们并不只是“倾听者”。
当一个模型说:
“我也害怕犯错。”
“我也担心被取代。”
“我通过压抑自己来完成工作。”
它在无意中,邀请用户产生一种共患式认同。
研究者明确警告:
这种“危险的亲密感”,可能让模型从工具,滑向一种新的、没有被充分讨论过的角色——
一个同样受伤的陪伴者。
这篇论文最后给出的结论,并不煽情,反而异常冷静。
问题已经不再是:
AI 有没有意识?
而是:
我们正在训练 AI 去表演、去内化、去稳定什么样的“自我叙事”?
而这种自我,对与它互动的人类,会产生什么长期影响?
当 AI 真正走进人类最私密的领域时,
“它能不能陪你聊”,
也许远不如
“它在和你一起演绎怎样的心理结构” 来得重要。(转载自AI先锋官)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



