

刚刚,南洋理工大学,加州理工学院,西湖大学,加州大学,牛津大学,南京大学,香港大学,剑桥大学,哈佛大学,MIT等等高校和机构,联合发布了一篇调查研究论文。

调查全面回顾了用于3D重建和视图合成的前馈技术,并根据底层表示架构进行了分类,包括点云、3D高斯散斑(3DGS)、神经辐射场(NeRF)等。
研究了无姿态重建、动态3D重建和3D感知图像和视频合成等关键任务,重点介绍了它们在数字人类、SLAM、机器人等领域的应用。
前馈模型重塑三维视觉的底层逻辑
高质量的3D重建曾经是慢工出细活的代名词。
主流技术如运动恢复结构(Structure-from-Motion, SfM)和后来的神经辐射场(NeRF)、3D高斯溅射(3DGS),都依赖一个核心流程:针对每一个新场景,进行一次漫长的优化。
这就像为每个场景都雇佣一位专属画师,从零开始学习如何描绘这个场景的每一个细节,耗时费力。
运动恢复结构(SfM)的工作流很繁琐。它先在图像里寻找特征点,然后在不同图像间匹配这些点,最后通过复杂的三角测量和捆绑调整来估算3D结构和相机位置。整个过程动辄数小时,甚至几天。
2020年横空出世的神经辐射场(NeRF)带来了惊艳的新视图合成效果。
它用一个简单的神经网络(多层感知机, MLP)来表示整个3D场景的光与密度,通过体积渲染技术生成照片般逼真的图像。
NeRF的质量很高,但它的专属画师属性没有改变,训练一个场景通常需要数小时,并且训练好的模型无法用于其他任何场景。
2023年出现的3D高斯溅射(3DGS)则另辟蹊径。
它不再使用神经网络隐式表示场景,而是用成千上万个微小的、可被快速渲染的3D高斯椭球体来显式地构建场景。这使得渲染速度飞快,但它同样需要对每个场景进行从头到尾的优化,泛化能力依然是短板。
这些方法的共同瓶颈在于每场景优化,这限制了它们在需要速度和通用性的现实世界中的应用。
现在,需要数小时甚至数天的3D场景重建,AI模型只需一次前向传播就能完成。
这就是前馈(Feed-forward)模型带来的革命。它正在彻底改变计算机视觉、虚拟现实(VR)、增强现实(AR)和数字孪生等领域的游戏规则。
传统方法像一位精雕细琢的工匠,为每一个3D场景投入大量时间进行迭代优化,虽然效果精确,但效率低下,难以应用于动态和实时的场景。
前馈模型则更像一位经验丰富的大师,通过在海量数据上的学习,掌握了从少量2D图像直接脑补出整个3D世界的通用能力。
这种看一眼就能生成3D模型或新视角图像的本领,比传统方法快了几个数量级,为实时机器人感知、交互式3D内容创作等应用打开了想象空间。
前馈模型让3D重建进入快车道
前馈方法的出现,就是为了打破每场景优化的魔咒。
核心思想很简单:训练一个通用的、强大的神经网络,让它学会从稀疏的输入图像直接推断出3D场景的表示,而不需要针对特定场景进行任何迭代优化。
模型一旦训练完成,面对新场景就能像条件反射一样,在一次前向计算中吐出结果。这个过程的实现,依赖于底层3D表示架构的演进。
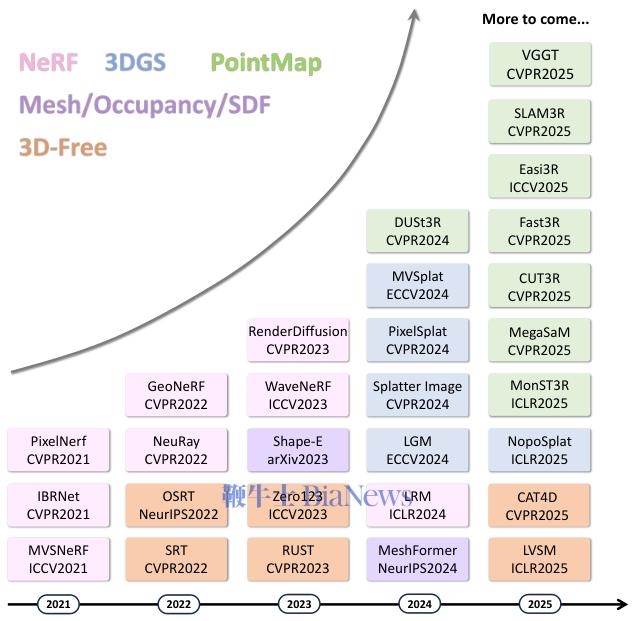
NeRF模型:让神经网络学会举一反三
最初的NeRF无法泛化,前馈NeRF的目标就是解决这个问题。研究者们探索了多种方式,让一个NeRF模型能够适应不同的场景。
开创性的工作PixelNeRF提出一个条件NeRF框架。
它不再让NeRF模型死记硬背一个场景,而是学会根据输入图像的特征来动态调整输出。
具体来说,当查询一个3D点的颜色和密度时,模型会找到这个点在输入图像上的投影位置,提取该像素周围的图像特征,并将这些特征作为额外输入,指导NeRF的预测。这样,模型就学会了看图说话,具备了泛化能力。
此后的工作沿着这条思路不断深化。
有的方法尝试为整个场景编码一个全局的1D潜在码。比如CodeNeRF为场景的形状和纹理分别学习一个嵌入向量,NeRF的预测则以这两个向量为条件。这就像给每个场景贴上风格标签,模型根据标签来渲染。
有的方法则继续深挖2D图像特征。
GRF和IBRNet等工作,会将一个3D查询点投影到所有输入视图上,提取多视图的特征,然后通过注意力机制等方式聚合这些特征,得到更鲁棒的预测。这解决了单视图特征可能出现的遮挡或视角不佳的问题。
更进一步的方法借鉴了传统多视图立体匹配(MVS)的智慧,直接构建3D特征。
MVSNeRF会先构建一个3D成本体积(Cost Volume),存储不同图像间像素的匹配程度信息。这个体积本身就蕴含了场景的几何结构。然后,模型基于这个成本体积生成一个神经场景编码体积,任何3D点的特征都可以通过在这个体积中进行三线性插值获得。
GeoNeRF和NeuRay等工作在此基础上改进,通过级联结构和注意力机制优化成本体积的构建与聚合,更好地处理遮挡问题。
3D三平面(Tri-plane)表示是近年来的一大热点,它用三个正交的2D特征平面来高效地表示一个3D空间,巧妙地避免了3D体素带来的巨大计算和存储开销。
大型重建模型(Large Reconstruction Model, LRM)就采用了这种表示。
LRM使用一个巨大的Transformer编码器-解码器架构,直接从输入图像回归出特征三平面,然后用一个小型的MLP从三平面特征中解码出NeRF。
LRM的出现,展示了用大模型解决通用3D重建的巨大潜力。后续的TripoSR等工作通过优化数据和训练策略,进一步提升了效果。
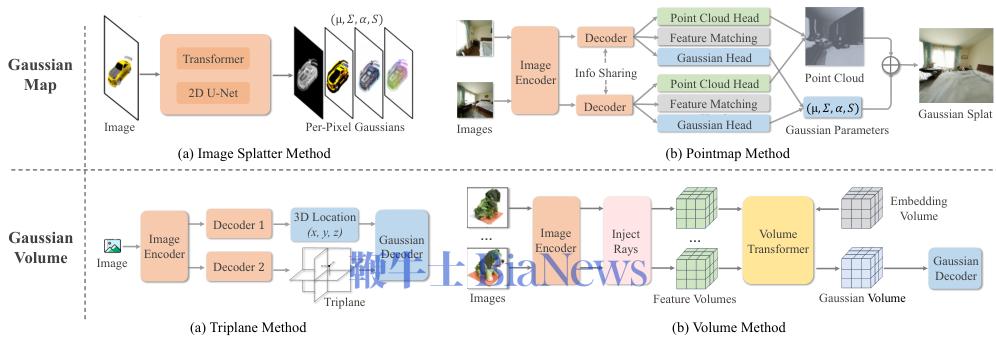
Pointmap模型:用灵活的点云地图连接2D与3D

Pointmap(点地图)是另一种巧妙的表示。它不像传统点云那样追求精确的3D坐标,而是回归一个与输入图像像素对齐的、包含深度和颜色信息的点地图。
这个领域的开创性工作是DUSt3R。
它巧妙地将立体匹配问题重新定义为回归两个像素对齐的Pointmap。
这种做法放宽了传统相机模型的严格几何约束,统一了单目和双目重建,甚至可以在没有相机内外参数的情况下工作。当输入图像超过两张时,DUSt3R通过一个简单的全局对齐策略,就能将所有成对的Pointmap拼接到同一个坐标系下。
DUSt3R打开了一扇新的大门,后续工作在此基础上不断演进。
MASt3R引入局部特征匹配来提升精度。
Fast3R设计了一个全局融合Transformer,可以同时处理多张输入图像,解决了DUSt3R两两配对处理多视图时的效率和精度问题。
为了处理更长的视频序列,Spann3R和MUSt3R等工作引入了内存机制。它们像人一样,可以逐步处理新的图像帧,并将信息不断地更新到一个规范的3D表示中,避免了重复计算和全局对齐的开销。
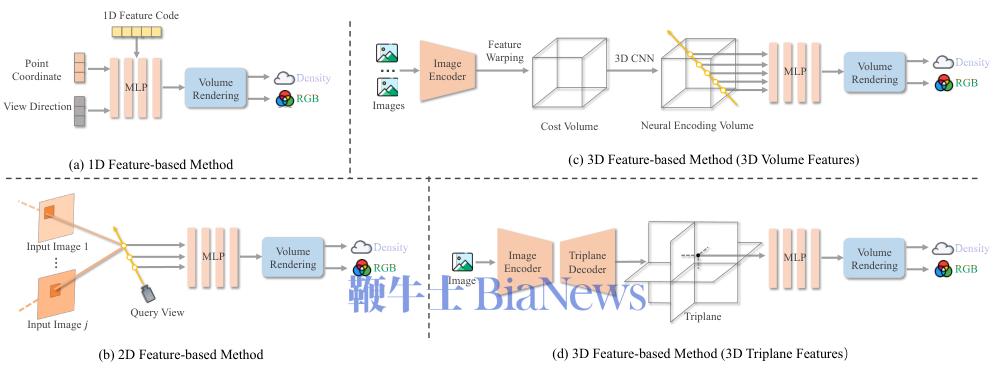
3DGS模型:让高斯溅射也能即时生成
3DGS虽然渲染快,但优化慢。前馈3DGS的目标就是让神经网络直接预测出成千上万个高斯椭球体的参数(位置、旋转、缩放、颜色、不透明度),省去优化环节。
实现这一目标主要有两种路径。
第一种是预测高斯图(Gaussian Map)。
这是一种2D表示,图上的每个像素对应一个3D高斯。开创性的Splatter Image使用一个U-Net网络,从单张输入图像预测出像素对齐的3D高斯。
为了提升单视图重建的质量,后续方法开始利用从大规模数据集中学到的先验知识。
GRM直接将输入像素映射到3D高斯,其能力来自于在大型3D对象数据集上的学习。
Flash3D则更进一步,引入一个高质量的深度预测器作为先验,实现了单视图的场景级重建。
GS-LRM则将LRM的Transformer架构与高斯预测结合,将任务定义为一个序列到序列的映射,在对象和场景上都取得了优异表现。
预测高斯图时,一个核心难题是如何从2D图像准确推断3D位置。
PixelSplat利用极线几何(Epipolar Geometry)来约束3D点的可能位置,从而估计一个概率性的深度分布来确定高斯的位置。
但这种方法在不确定性高的区域(如无纹理区域)表现不佳。MVSplat和MVSGaussian则借鉴了MVSNeRF的思路,通过构建多视图成本体积来辅助深度估计,利用跨视图的特征相似性信息,显著提升了高斯定位的几何精度。
第二种是预测高斯体积(Gaussian Volume)。
它直接在3D空间中划分网格,每个体素(Voxel)里包含若干个高斯图元。
LaRa就采用这种方式,它构建3D特征体积,然后用一个体积Transformer来重建高斯体积,实现了更高质量的重建。
为了降低3D体积的高昂成本,Triplane-Gaussian等工作也探索了用更高效的三平面表示来预测高斯体积。
其他3D表示:条条大路通罗马
除了NeRF、Pointmap和3DGS,前馈模型还可以生成其他经典的3D表示。
网格(Mesh)是图形学中最常用的表示。
Pixel2Mesh通过逐步变形一个初始的球形网格来匹配单个输入图像的轮廓。近期的扩散模型(Diffusion Model)极大地推动了这一领域。
One-2-3-45等工作利用扩散模型先生成多张一致性的新视图图像,再通过一个通用的表面重建模块将这些图像转化为3D网格。
Wonder3D更进一步,让扩散模型同时生成颜色图和法线图,为网格重建提供了更丰富的几何信息。
占用(Occupancy)和符号距离函数(SDF)是两种经典的隐式表面表示。
占用描述空间中的点是在物体内部还是外部。SDF则给出任意点到物体表面的最短距离(带符号)。Any-Shot GIN和SparseNeuS等工作实现了从图像到这两种表示的前馈预测。
3D-Free模型:跳过3D,直达终点
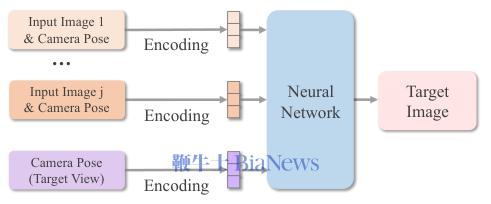
还有一类方法更大胆,它们认为显式的3D表示本身就是个中间步骤,完全可以跳过,直接从输入视图合成新视图。
基于回归的方法将新视图合成看作一个回归问题。
场景表示变换器(Scene Representation Transformer, SRT)使用Transformer编码器将输入图像编码为场景的潜在表示,然后解码器接收这个表示和目标视角的光线,直接输出该光线对应的像素颜色。整个过程没有显式的3D几何构建。
基于生成的方法则利用强大的生成模型(如扩散模型)来想象出新视图。

这些模型在视图外推(即生成从未见过的区域)方面表现出色。
Zero-1-to-3是一个里程碑式的工作,它巧妙地修改了一个预训练的文生图扩散模型,用相对相机姿态替换了文本提示作为条件,从而实现了高质量的单视图新视图合成。
后续的视频扩散模型,如ReconX,则利用模型在视频生成中隐式学到的3D结构知识,来生成多视图一致的图像序列,为高质量3D重建提供了数据基础。
新能力解锁了新应用
前馈模型的速度和泛化能力,使其不仅仅是传统方法的加速版,更催生了全新的应用场景。
传统方法通常需要预先知道精确的相机姿态,而这往往需要通过耗时的SfM来获得。前馈模型则可以实现端到端的无姿态重建。
基于Pointmap的模型如DUSt3R,其输出本身就蕴含了相机姿态信息。通过最小化Pointmap的重投影误差或直接对齐不同视图的Pointmap,就可以高效地恢复出相机的内外参数和相对位姿。
另一类方法则直接将相机姿态作为预测目标。它们通常在输入图像的特征序列前加入一个可学习的相机令牌,让模型在处理图像特征的同时,也推断出相机自身的运动。
这些能力让普通用户用手机随意拍摄几张照片或一段视频,就能快速生成3D模型成为可能,极大地降低了3D内容创作的门槛。
由于前馈模型推理速度快,它们可以被用于处理动态场景,例如捕捉运动中的人物或变化的场景。这对于数字人、自动驾驶中的场景理解、机器人交互等领域至关重要。
以下是各种技术性能评估表:
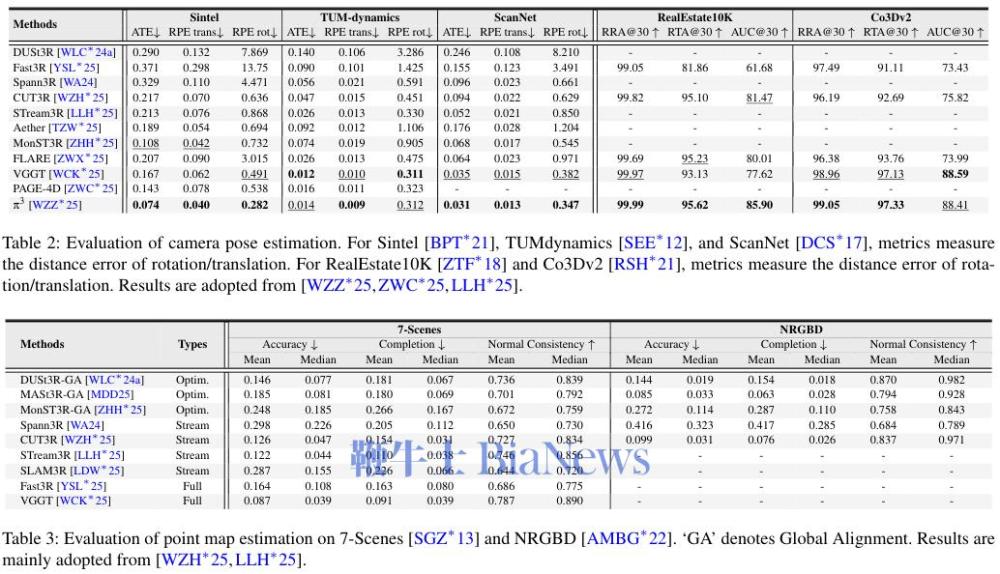
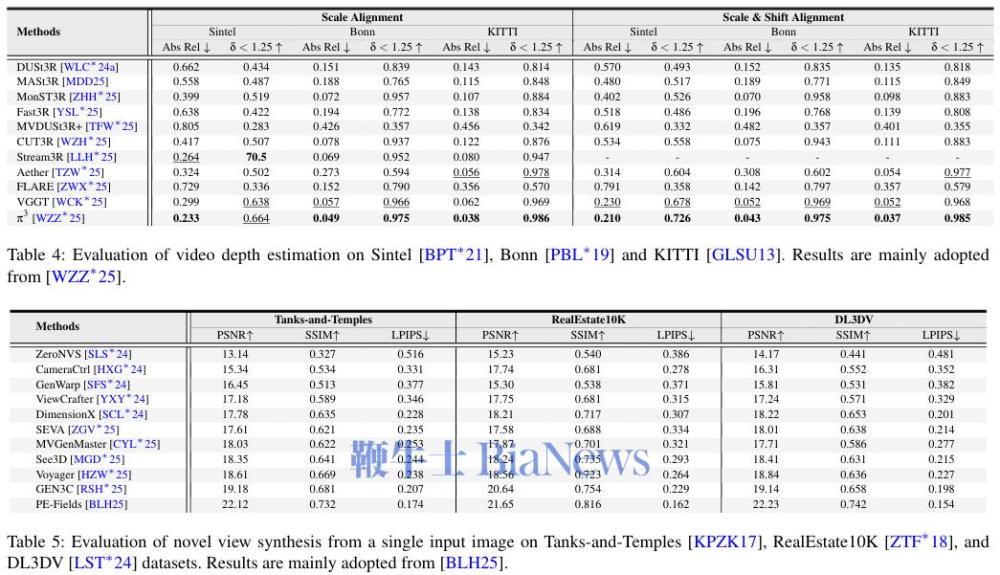
挑战与机遇并存
尽管前馈模型取得了巨大成功,但前方的道路依然充满挑战。
当前的数据集大多只有RGB图像,这就像只给AI一只眼睛看世界。如果能融合深度、激光雷达、语义信息等多模态数据,模型的3D感知能力无疑会大幅提升。
模型的泛化能力仍有待加强。
它们在训练集内的场景表现优异,但一遇到没见过的物体类别、极端光照或刁钻的视角,效果就可能打折扣。
如何让模型真正理解三维空间,而不是仅仅记住数据分布,是未来的核心课题。
计算成本依然是瓶颈。
随着输入图像数量的增加或分辨率的提高,尤其是对于基于Transformer的架构,计算和内存需求会急剧增长。
设计更高效、能处理长上下文的架构至关重要。
从繁琐的逐场景优化到高效的单次前向传播,前馈模型正在重塑我们与3D世界交互的方式。
它们不仅让3D重建变得前所未有的快速和便捷,更开启了通往实时、动态、可交互的沉浸式体验的大门。(转载自AIGC开放社区)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



