

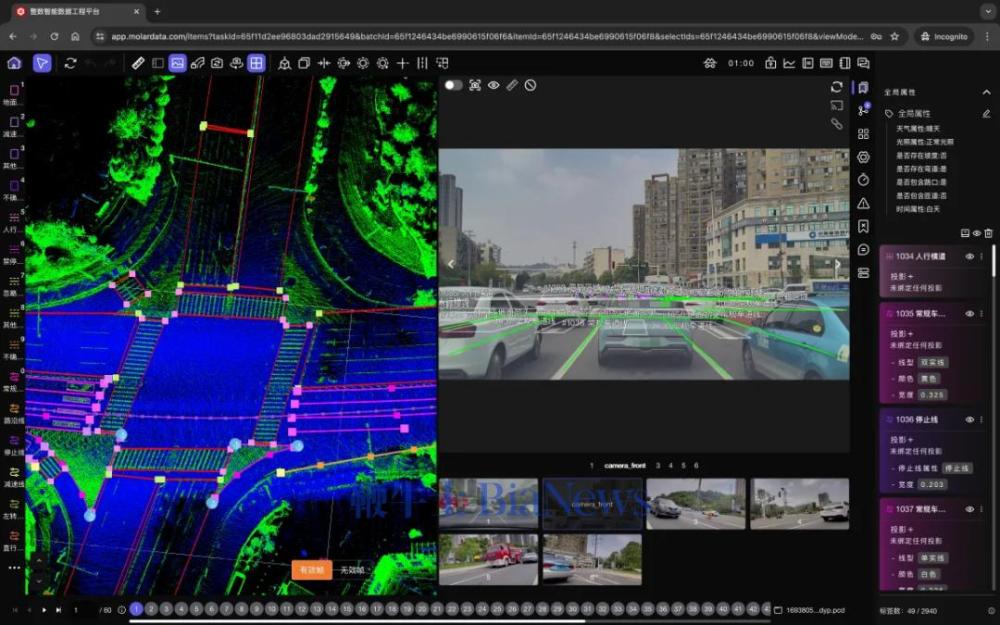
7月23日,在封闭高速路段上,懂车帝对36款“智驾”车型进行了多个特殊场景测试,包括“高速施工”、“匝道遭遇野蛮加塞”、“横穿的猪”等,毫无意外,这都属于长尾场景。虽然关于猪的测试通过率最低(窜入高速的猪是典型的“非结构化”对象,通常没可能训练到),但“消失的前车”引发共鸣最多。大概因为这种场景很多人经历过,因为惊险,所以印象深刻。
AEB与高速NCA的冲突
按照懂车帝的设定,测试车(以下称“本车”)以时速120 km/h跟随前车行驶,前车突然向左变道躲避本车道事故车,猝不及防的本车,需要在极短时间内完成感知-决策-执行闭环。36辆车,只有5辆车成功做出了规避动作。
这一测试,当然是不严谨的——因为每辆车面临的场景条件变量不一致。有的车测试时左车道是空的(后车稍远),有规避空间;有的车面临左道被占,很难绕行。这就造成了结果可信性不高。尽管如此,结果仍然有一定参考价值。就像懂车帝自己说的,重要的不是第几,而是人是否安全。
“消失的前车”,场景设置非常有技巧,它恰好击中了智驾系统薄弱的结合部——AEB(自动紧急制动)和高速NCA(导航辅助驾驶)的冲突问题,不管品牌方是否将两个功能融合在一起。
在感知层,本车需要识别左侧车流与突然出现的前方静止障碍的双重威胁;决策层需要做出决定,变入左道车流空档内,还是强力制动;执行层则需要AEB和NCA协同。
实际测试中,多车出现严重失误。懂车帝也出来解释说,很多车型在AEB被触发后,NCA功能被抑制,导致车辆硬刹,结果是制动距离不够,仍然撞上障碍物。这还算好的,更多的车型根本没有识别最大的威胁——本车道前方静止障碍,导致一头撞上去。减速很少或者压根没有减速。
无论AEB还是NCA,感知层不管有多少个传感器源,都是同一组。而决策层则有两个模块,而且不能同时主导。不过,这只是表面上的模块冲突导致决策非最优。
静态决策导致孤立响应
当前主流智驾普遍采用端到端架构。端到端的设计思想,就是将传感器输入通过神经网络,直接映射为驾驶控制信号,减少中间模块误差传递的影响,也避免规控模式覆盖空白导致系统失能。
人类熟练驾驶,即便面对极端场景,基本都是下意识反应,这和端到端思路有共同之处。但差别在于,即便电光火石间,人类驾驶员做出决策,也是依据“连续时帧”画面做出决断,而非单纯依靠一个画面做出。前者意味着即便做出决断,随着时间流逝发现新的、更严重威胁,也能及时矫正,采取新对策(是否成功另说)。
而很多端到端模型采取静态数据输入(单帧画面或者短时间窗口),忽视驾驶行为本质上是一个强时序相关的连续决策过程。缺乏时序建模,导致一些需要随机应变的场景中,智驾系统表现出呆板、控制漂移、变线失稳等。
在“消失的前车”场景中,前车紧急刹车-躲避障碍-左道车(如果有理智的话)刹车让行等行为,站在本车观察角度,形成了复杂的“信号链”。本车根据这些时序信号,也应该形成一个策略序列,而不是孤立的一个策略。智驾有时显得很傻,道理就在这,即静态决策必然导致孤立响应。

智驾判断缺乏随机应变性,有时候就显得很傻
更复杂的是,其他交通参与者给出的信号,往往具有多义性。同一个驾驶员即便面对非常类似的场景,也可能采取不同策略,均为合理行为。但如果这些行为都作为数据输入,容易模型学习方向不确定,训练震荡。如果多个驾驶员处理类似场景风格不同,模型学习到的控制行为,可能飘忽不定。最终在高压场景(比如本文需要极短时间内决断的场景)下,“既不充分制动也不果断变道”的折衷决策,貌似温和,其实是最坏的选择。
端到端架构中,前帧感知偏差(如误判左侧车流速度)会通过Transformer等序列网络不断放大。测试中车辆向左变道时轨迹线突然消失,正是时序误差累积的典型表现。
为什么不用“长时帧”
如果简单认为,采用连续帧训练就能解决此类困境,可能有点天真了。要考虑为什么不倾向于用长时间连续帧训练。
第一个理由,容易跳帧。如果连续帧间的目标ID、轨迹或意图标注不一致,会导致模型误认为是两个完全不同的事件,进一步削弱其对跨帧语义的建模能力。简单说,就是系统认为这是两个完全风马牛的事,导致同一目标在两帧中出现“跳帧”、“漂移”甚至“消失”,这可真成了“消失的前车”了。
连续帧不仅记录时空变化,更为关键的是提供了其他交通参与者的真实意图。人类司机不也是靠着连续观察,判断旁道车辆到底想直接加塞,还是想让行后再加入进来——对行人意图的判断更是如此(因为其没有转向指示灯)。
优化后的标识呈现
个别端到端系统,和人类判断的方式差不多,也将行为意图作为显式标识,通过多目标轨迹回归进行建模。前提是需要在一定时序内创建客体(其他车或行人)ID一致性标签。防止跳帧、丢失客体观察。
这就引出了第二个理由,成本问题。长时帧的标注和ID标签训练成本太高了,大家都鼓吹无/轻标注和无监督学习,这让静止帧训练成了现实选择。
长序列不仅要求高质量时空数据样本,还依赖强化标注,大大扩张了数据量。对大模型和转移之后的车端小模型构成更多算力压力。很多品牌已经注意到连续行为数据的采集、标注与利用。但从这次懂车帝测试情况来看,成果尚未反映到模型训练和转移。
不过,目前业内多品牌的端到端系统,比以前更重视“连续语义行为”的训练,尽量模拟人类随着时序所做的连续决策与执行。目标是让系统变得更稳健可信,构建有清晰合理责任边界的系统,而不是到关键时刻自己掉链子要求接管的甩锅系统。
我们应该相信,随着技术发展,智驾将越来越理智,并最终接管人类驾驶。在此之前,还是要谨慎宣传,避免误导公众。(转载自:新浪汽车)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



