

当下,人工智能领域的竞争已进入白热化阶段,其激烈程度不仅体现在技术突破和产品迭代上,更集中于对核心人才的争夺。
近期,OpenAI 与 Meta 之间爆发的“挖角大战”便是这一现象的缩影:Meta 不惜重金,成功从 OpenAI 挖走 8 位顶尖研究者,甚至传闻扎克伯格亲自下场,开出高达 1 亿美元的天价“转会费”——这个过去常见于体育圈的词,竟然也进入了AI行业。以至于 OpenAI 不得不宣布全员放假一周,以应对这场突如其来的“人才危机”。虽然Sam Altman声称核心团队不受影响,但是显然先例一开,人心浮动已经在所难免。
下面这张互联网上传播的著名照片,列出了Meta最近网罗的顶尖人才,其中包括了GPT-4o语音系统的主创、Gemini前技术负责人、ChatGPT核心架构师等,华裔面孔占了大多数,侧面印证了黄仁勋在演讲中提到的一句话:“全球有一半AI开发人员都是中国人。”
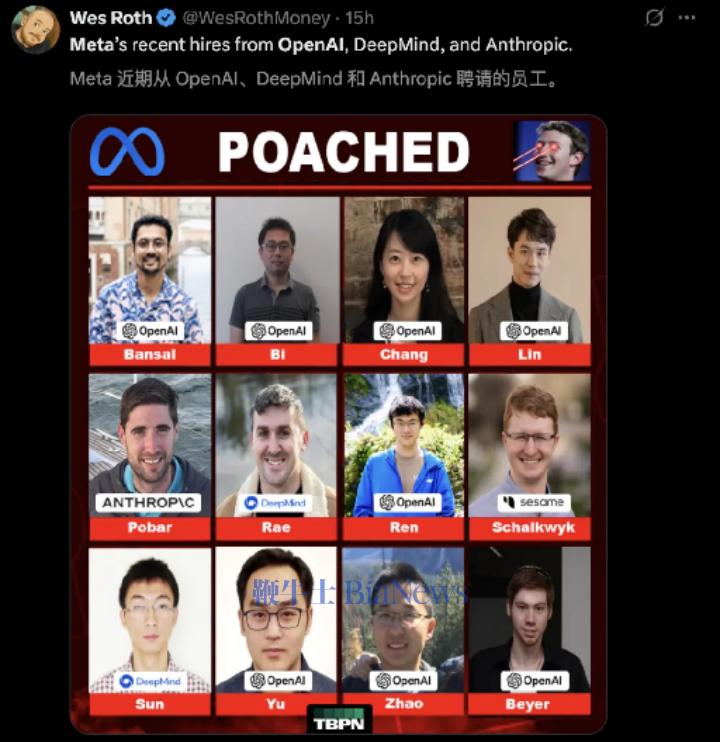
更不要说在几周前,Meta以143亿美元天价,收购数据标注公司Scale AI的49%股权,并挖角华裔天才Alexander Wang担任新设立的超级智能实验室(Superintelligence Labs)的负责人。
这不仅是一场商业竞争,更是一场没有硝烟的“战争”,深刻揭示了在 AI 大模型演进的关键时期,顶尖人才的稀缺性和决定性作用。
笔者曾在去年6月,在本公众号上刊文《这幢三层小楼,藏着OpenAI步步领先的“灵魂密码”》,分析了OpenAI内部人才的独特优势。今天这些价值,已经不光体现在OpenAI这两年来持续推出的4o、o3、4.5等先进模型上,也转化为了实实在在的支票。
那么,为什么顶尖AI人才会这么值钱?这是本篇文章分析的主题,笔者将从直接原因、深层原因和长期影响这三个角度来剖析此次人才大战的底层逻辑。
直接原因:
头部AI企业的竞争日趋白热化
Meta面临落后压力
Meta 对 OpenAI 核心研究人员的“连锅端”式挖角,不仅是对竞争对手技术力量的直接削弱,更是对自身AI战略的孤注一掷。
事实上,对顶尖AI人才的争夺并非今日才有。
2012年,杰夫·辛顿(Geoffrey Hinton,2024年诺贝尔物理学奖得主)与学生亚历克斯·克里泽夫斯基(Alex Krizhevsky)和伊利亚·苏茨克维(Ilya Sutskever,OpenAI的前任CTO)共同开发的AlexNet模型,在李飞飞发起的ImageNet大规模视觉识别挑战赛中以惊人的准确率赢得了冠军。之后几个月,一场围绕他们团队的“拍卖”便已悄然上演。
当时,辛顿教授带着他的两位学生,坐镇西雅图的丽思卡尔顿酒店,将仅有他们三人的公司(DNN Research)摆上了“货架”。谷歌、Facebook、百度等全球科技巨头纷纷前往竞标,最终,谷歌以数千万美元的价格赢得了这场竞赛,将三人集体收入麾下,这被视为谷歌在AI领域取得领先地位的关键一步,也是AI领域首次重金收购团队的先例。
凯德·梅茨记录人工智能发展历史的著作《深度学习革命》对这段历史有着非常生动的描述,详细到了辛顿每天晚上怎么和学生们讨论各家的报价和回复策略。

▲ 辛顿AlexNet团队合影,当时的伊利亚还头发茂盛。
来源:https://www.wired.com/2013/03/google-hinton/
在过去的十余年间,AI技术飞速发展,但对顶尖人才的渴求却始终如一,甚至愈发强烈,这背后是头部AI企业之间的激烈竞争。
Meta的LLama曾经是开源模型领域的佼佼者,事实上在过去几年中,大量自称“首创”的模型,都是来自于对于LLama的“套壳”。但是在去年年底DeepSeek v3横空出世之后,LLama已经逐步落后,目前在Huggingface Leaderboard排名中已经降到了20名开外:
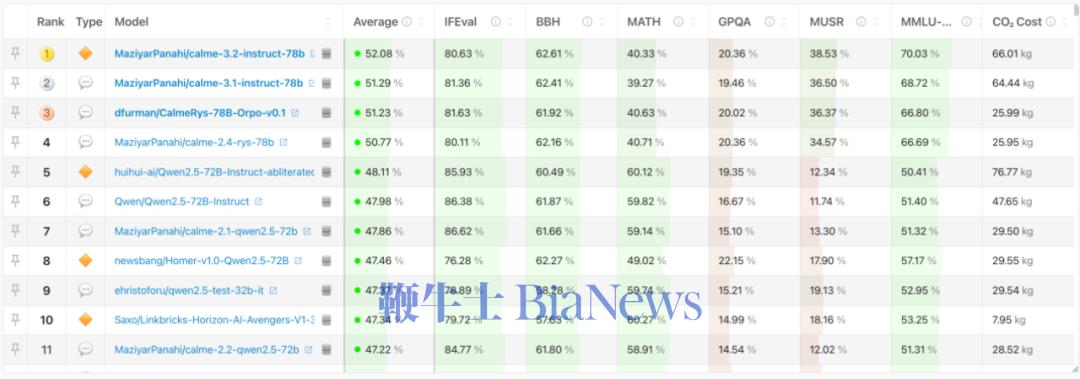
▲Huggingface 开源模型排行榜,基于LLama的模型已经排到了20名以外,而基于阿里千问的模型成为主流。
来源:https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/
为此,Meta在五月份仓促推出了Llama 4,虽然发布时各项数据相当亮眼,但是经过网友实际评测,性能远远不及预期。甚至有爆料称,为了提升模型在基准测试中的表现,Meta可能在训练过程中将测试集数据混入训练数据中,这种做法相当于提前在备考中“泄题”,有作弊的嫌疑。
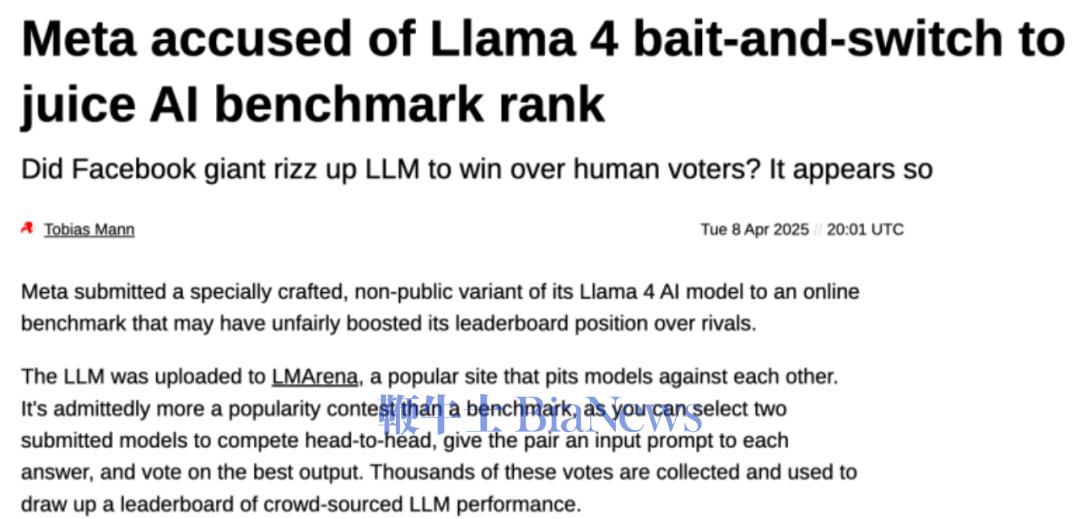
▲ 媒体报道Meta在Llama4开发中有作弊行为。
来源:https://www.theregister.com/2025/04/08/meta_llama4_cheating/
面临着最近几个月来谷歌Gemini 2.5的出色成绩和OpenAI、Claude等竞争对手的高歌猛进,扎克伯格的压力可想而知。为了挽回败局,不得不祭出“重金之下必有勇夫”的招数。
深层逻辑:
AI大模型从“感性”、“知性”到“理性”的演进趋势
康德曾把人的能力,分为感性、知性和理性。在这里,我们也可以借用对人类智能的认知框架,来分析人工智能的发展。当前,AI大模型的发展正经历一个关键的转折点:
以李飞飞在2008年推出包含1500万照片的ImageNet为标志,AI逐步形成了对世界的感知(即“感性层面”)。在此基础上,基于上万亿语料的大语言模型逐步过渡到了“高度依赖数据和算力的预训练模式”(即“知性”层面)。今天,大模型又在向更深层次的“基于深度思考的后训练模式”(即“理性”层面)迈进。如何理解这一演进,是理解为何顶尖研究人才如此重要的核心。
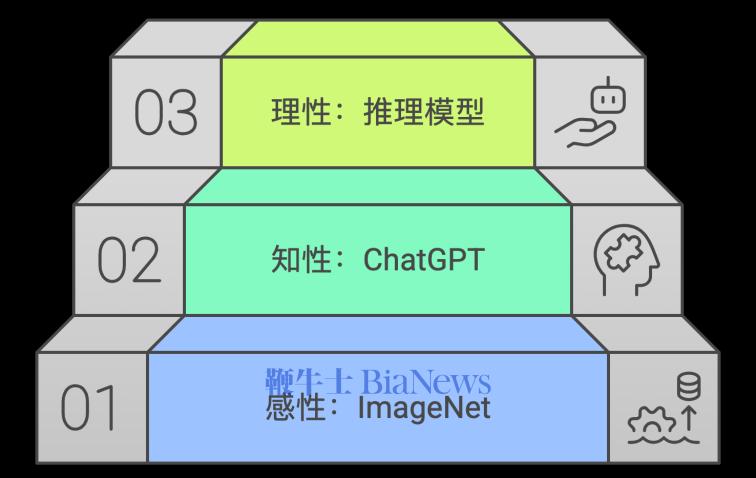
▲ 大模型发展的三层阶梯,与人类认知的“三性”相符
一
“知性”阶段:数据和算力的胜利
在过去几年,特别是大语言模型和扩散模型的崛起,很大程度上是“规模法则”(“Scaling Law”)的胜利:只要模型足够大(体现在参数多少)、数据足够多、算力足够强,AI的性能就能呈现出可预测的、接近指数级的提升。这也是一些发达国家一度认为,只要控制住了源头算力,就把握住了AI发展命脉的原因。
在这个阶段,AI模型主要展现出的是“知性”能力。
所谓知性,是指模型通过海量数据学习到的模式识别、关联记忆和经验归纳能力。它能够精准地感知信息、流畅地理解语言、高效地生成内容,并展现出令人惊叹的连贯性。例如,大语言模型可以写诗、写代码、进行多轮对话,图像生成模型能够绘制出各种风格的图片。
这些能力,本质上是基于对海量数据的深度“学习”和“举一反三”,从中归纳出了复杂而丰富的“世界知识”,但这种知识更多停留在对现象的“知其然”。
在“知性”阶段,相对于顶尖人才,数据规模和计算资源才是决定胜负的核心驱动力。谁能投入更多的算力,谁能喂给模型更多高质量的数据,谁就能训练出更大、更强大的模型,从而在“知性”层面取得更优异的表现。
二
“理性”阶段:后训练的深水区
然而,随着模型规模的不断扩大,“知性”能力的边际效应逐渐显现,大模型开始暴露出其内在的局限性。大模型在逻辑推理、复杂问题解决、规划决策、以及与人类价值观对齐等方面,仍然存在显著短板。
ChatGPT o1为首,DeepSeek R1跟进的“推理模型”,在算力和数据限定的情况下,通过在推理阶段(即根据用户提问产生回答的过程中),以“边想边答”的形式,大大提升了模型输出的完整性和复杂性。

这正是 AI 大模型正在迈向的“理性”阶段。
所谓理性,指的是模型能够进行抽象推理、逻辑演绎、复杂规划、因果判断,并与人类价值观深度对齐的能力。它不再仅仅是基于模式的“知其然”,而是能够“知其所以然”,甚至能够进行“反事实推理”和“道德判断”。
在迈向“理性”的过程中,大模型还面临着一个突出挑战——“幻觉”(Hallucination)问题。这是指模型在生成内容时,看似流畅自然,但却包含事实性错误、逻辑不一致或无中生有的信息。
幻觉的产生,恰恰暴露出模型在“知其然”(模式识别与关联)层面的强大,但在“知其所以然”(逻辑、因果、常识)层面的不足。它也是目前限制很多政府、企业在应用大模型方面却步不前的症结所在。
为了让AI不仅“能干”,更要“可靠”、“负责”,“可信AI”(Trustworthy AI)成为“理性”阶段的核心目标。可信AI通常包含以下五个关键支柱,它们是构建未来智能社会的基石:
可解释性:我们能否理解AI做出某个决策的内在逻辑?知道“为什么”模型会给出这样的结果,而非一个无法洞察的“黑箱”。
鲁棒性:模型在面对恶意攻击(如对抗样本)、数据扰动或非预期输入时,能否依然保持稳定和准确的性能,不被轻易“欺骗”。
公平性:确保模型在不同群体、不同场景下,不会产生偏见或歧视性的结果,避免算法歧视。
隐私性:在数据使用和模型训练过程中,严格保护用户和敏感信息的隐私,避免数据泄露。
安全性:防止AI系统产生有害或危险的输出,确保其行为安全可控,不被滥用。
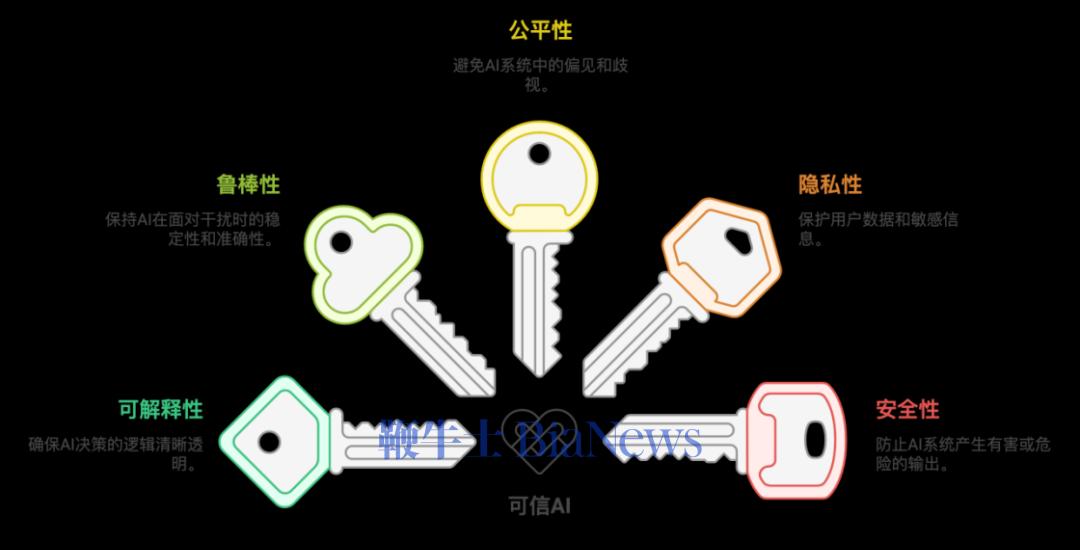
▲ 构建可信AI的五个关键支柱。
“理性”阶段的突破,是AI从“智能工具”走向“智能伙伴”的关键。它要求模型不仅“能说会道”,更能“明事理,懂人情”,并且能够被信任。
这是一场对AI模型进行“深度思考”和“价值观塑造”的过程,不再只能依靠单纯地堆砌数据和算力,跟读依赖于“后训练”阶段的精细化工作,具体手段包括:
●对齐:通过更精细的人类反馈强化学习(RLHF)等机制,让模型的目标与人类的价值观、意图深度对齐,从而有效减少“幻觉”和有害内容的生成。
●指令微调:让模型更好地理解人类的复杂指令和意图,并按照指令生成高质量、有用的回复,提升其“听话”和“办事”的能力。
●思维链(CoT):在DeepSeek或者豆包这样的产品中,选中“深度思考”选项,生成的思考过程,即为“思维链”。引导模型进行多步骤的逻辑推理,展现出类似人类的思考过程,让其决策过程更透明、更可控。
●复杂推理与规划:开发新的算法和训练范式,引入更多具有因果关系的数据和知识图谱等结构化知识,让模型能够解决需要多步逻辑、复杂规划的难题,真正从数据关联走向因果理解。
●数据优化:不再仅仅追求数据量,而是更注重高质量、高信噪比的数据,并引入更多具有逻辑和因果关系的数据,提升模型的“理解力”。
这是DeepSeek等后起之秀得以在算力受限的情况下一定能够取得出色成绩的原因,这正是顶尖研究人员发挥个人价值的机遇所在。
一言以蔽之,在AI大模型从“知性”走向“理性”的深水区,顶尖研究人才的价值,已经超越了单纯的工程实现,他们是AI思想的策源地,是算法创新的灯塔,更是确保AI安全、可信、负责任发展的压舱石。他们的每一次突破,都将重新定义AI的边界,并决定人类与智能共舞的未来图景。
这是今天,顶尖AI人才变得炙手可热的深层次原因。
人才争夺战的深远影响与启示
AI人才争夺战的白热化,不仅仅是科技巨头之间的资本游戏,对整个行业、社会乃至个人都将产生深远影响。
一
对企业而言:人才战略是核心竞争力
一家企业能否在 AI 浪潮中立于不败之地,其人才战略将是重中之重。这不仅包括高薪挖角,更包括构建开放的研发文化、提供充足的计算资源、营造自由的学术氛围、以及给予研究者充分的信任和发展空间。得人才者得天下,这句古老的箴言,在AI时代被赋予了全新的、更深刻的内涵。
二
对行业而言:加速创新与潜在垄断
人才的流动,在一定程度上会加速 AI 前沿探索和技术突破,因为思想的碰撞和知识的传播会更加频繁。然而,过度集中的人才争夺,也可能导致人才虹吸效应,使得资源和人才向少数头部企业集中,加剧行业垄断,不利于中小企业和初创公司的发展。这既是创新的加速器,也可能是行业生态平衡的潜在破坏者。
三
对个人而言:研究能力与创新思维是未来核心
对于每一位身处 AI 浪潮中的从业者,无论是开发者、产品经理还是测试人员,此次人才争夺战都敲响了警钟。未来工作中,“人”的核心竞争优势和价值将如何被重新定义?那些“机器难以替代”的能力,正是我们需要重点培养的:
深度的研究能力:理解模型底层原理,提出新的算法和架构。
批判性思维与创新能力:质疑现有范式,探索未知领域,提出原创性解决方案。
跨学科知识与整合能力:将AI与其他领域(如社会学、心理学、伦理学)结合,解决复杂问题。
与AI协作的能力:学会驾驭 AI 工具,将其作为自己的“智能副驾”,提升效率。
在AI的巨浪面前,唯有不断学习,提升不可替代的“人类智慧”,方能立于不败之地。
四
对社会而言:平衡发展与公平流动
社会需要思考如何平衡技术进步与人才的公平流动,避免出现“人才孤岛”和“数字鸿沟”。政府、高校、企业应共同构建更加开放、包容的AI人才培养体系,鼓励基础研究,促进知识共享,确保AI发展的红利能够普惠大众。AI的未来,不仅是技术的未来,更是人类社会的未来,其发展必须以人为本,兼顾公平与普惠。
结语
从2012年辛顿教授团队的“拍卖”,到今天 OpenAI 与 Meta 的“人才大战”,AI领域对顶尖智慧的争夺从未停止。这不仅仅是商业利益的驱动,更是AI大模型从“知性”向“理性”深层演进的必然结果。
当AI模型的未来不再仅仅依赖于数据的简单堆砌,而是需要更深层次的逻辑推理、价值观对齐和通用智能时,人类顶尖研究者的独特洞察力、创新思维和理论突破能力,就变得无可替代。
这场没有硝烟的“战争”提醒我们,在追逐技术奇点和商业成功的道路上,对人才的尊重、培养和争夺,将始终是决定胜负的关键。因为,最终定义AI未来的,不再是冰冷的数据和算力,而是那些拥有智慧、远见,并肩负社会责任的人类大脑。(转载自数字社会发展与研究)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



