

清华等发布大模型基准测试工具AgentBench
8月7日,来自清华大学、俄亥俄州立大学、加州大学伯克利分校的研究人员们在预印本平台arXiv发表一篇新论文,介绍了一个面向大型语言模型的多维基准测试工具AgentBench。
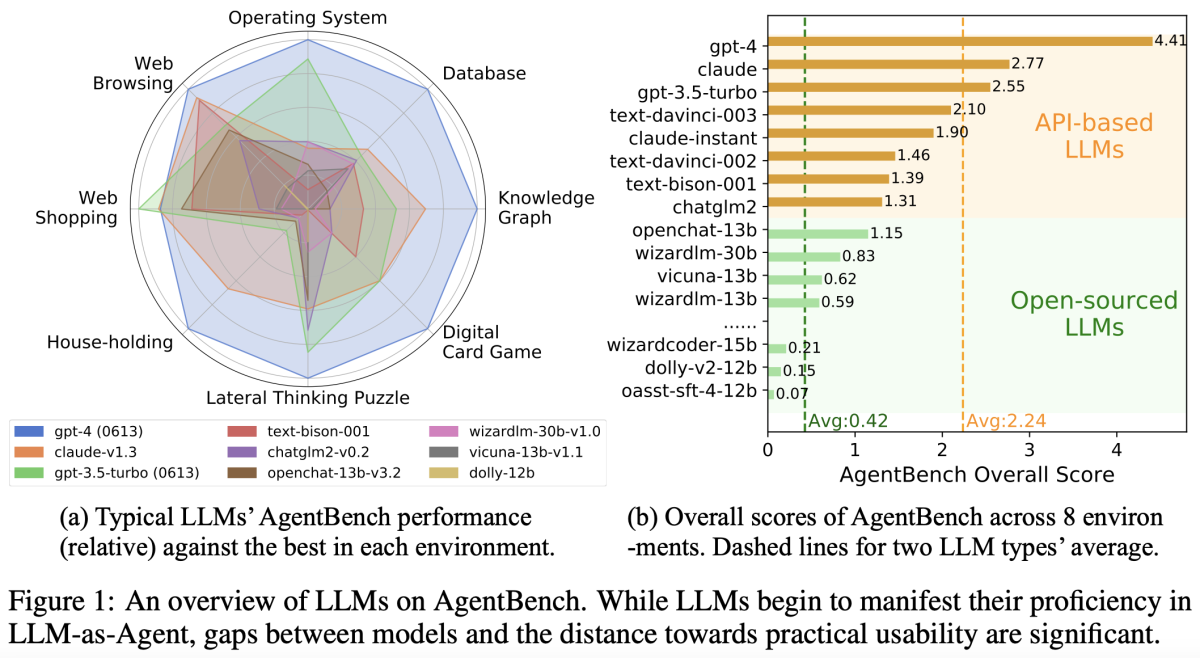
AgentBench由8个不同的任务组成,可评估大语言模型在多轮开放式生成环境中的推理和决策能力。
研究团队对25个大型语言模型的广泛测试表明,顶级商业大型语言模型在复杂环境中表现出强大的代理能力,但它们与开源竞争对手之间的性能存在显著差异。
根据测试结果,GPT-4表现最佳,Claude和GPT-3.5分居第二、第三名。
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



