

过去两年,大语言模型的数学推理成绩一路飙升,AIME24、AIME25 等主流评测榜单上,领先模型正确率普遍突破 90%。数学曾经是 AI 最能体现“思维能力”的试金石,但如今却因为题库公开、评测饱和、泄题风险等问题,逐渐丧失区分度,“越考越简单”。
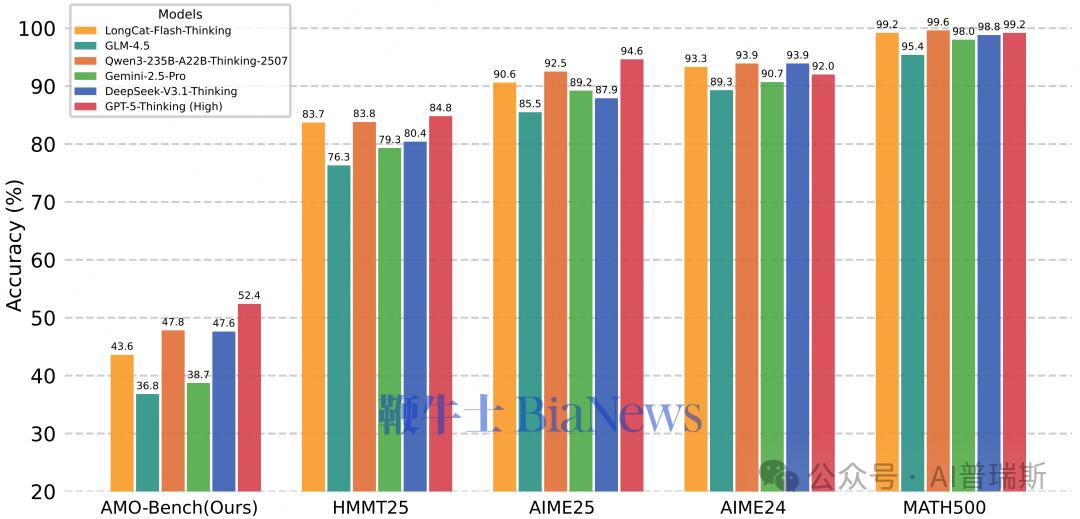
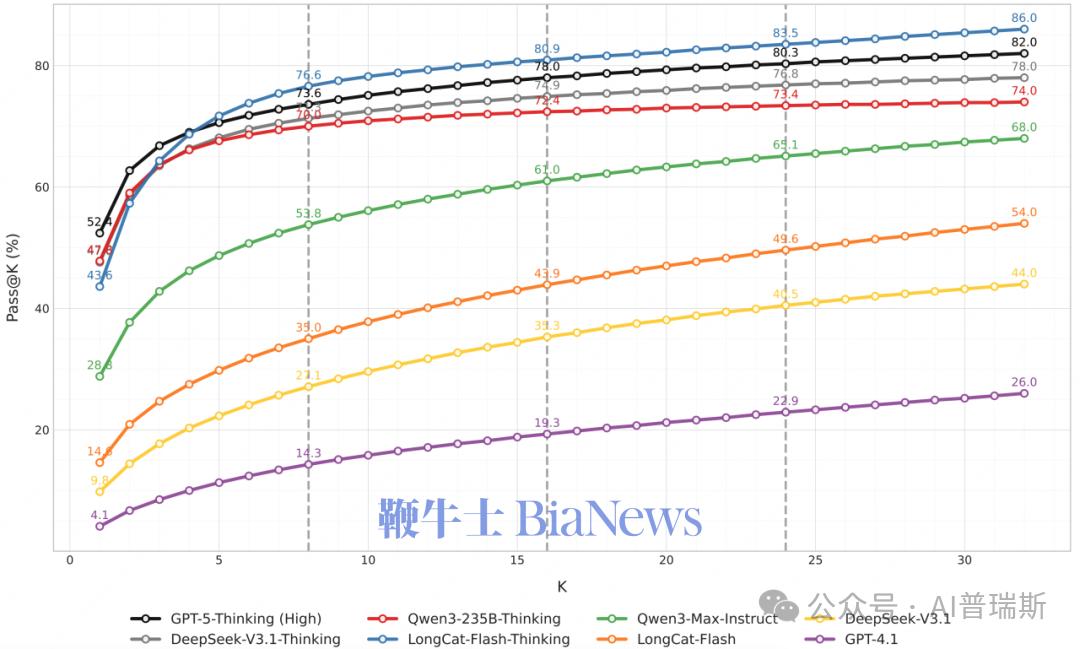
在这样的背景下,美团 LongCat 团队推出了全新的高难度数学推理评测:AMO-Bench。这套基准由 50 道竞赛专家原创题目构成,难度整体对标甚至超越国际数学奥林匹克(IMO)。首轮测试中,即便是顶尖的 GPT-5–Thinking,在 32 次机会下平均正确率也只达到 52.4%,绝大多数模型甚至不足 40%。换句话说:现阶段所有大模型在真正的高阶数学推理面前,依然远离“及格线”。
为何必须有 AMO-Bench?因为旧的评测已经被模型“读透”了
LongCat 团队指出,主流数学评测几乎都来自公开竞赛题库,模型可能在训练中“看过答案”,真实能力被高估。同时,AIME、HMMT 等 benchmark 已经接近满分状态,已经无法推动模型继续在推理深度上提升。
即便直接使用 IMO 原题进行评估,也存在新的问题:大多数 IMO 题为证明题,必须人工批改,一道题可能耗费 30 分钟,难以规模化评测。
行业急需一套高原创 + 高难度 + 可自动化评分的评测方案,而 AMO-Bench 正好同时满足三点。
AMO-Bench 如何打造?四道关卡把题目“打磨到极限”
LongCat 团队为此建立了严格的构建流程:
①专家原创
所有题目均由有奥赛经历的专家独立设计,并附带详细的 step-by-step 解题路径,方便校验逻辑。
②三重盲审
至少三位专家独立审题,确保题意清晰、难度到位、不超纲。
③去重与原创性核查
结合文本匹配、互联网检索和人工审核,严格避免与现有题库相似,避免模型“记忆命中”。
④难度双审
候选题必须让顶尖模型连续三次无法全对,同时需专家再次确认难度不低于 IMO。
结果就是:每道题都“尖锐、干净、原创、够狠”。
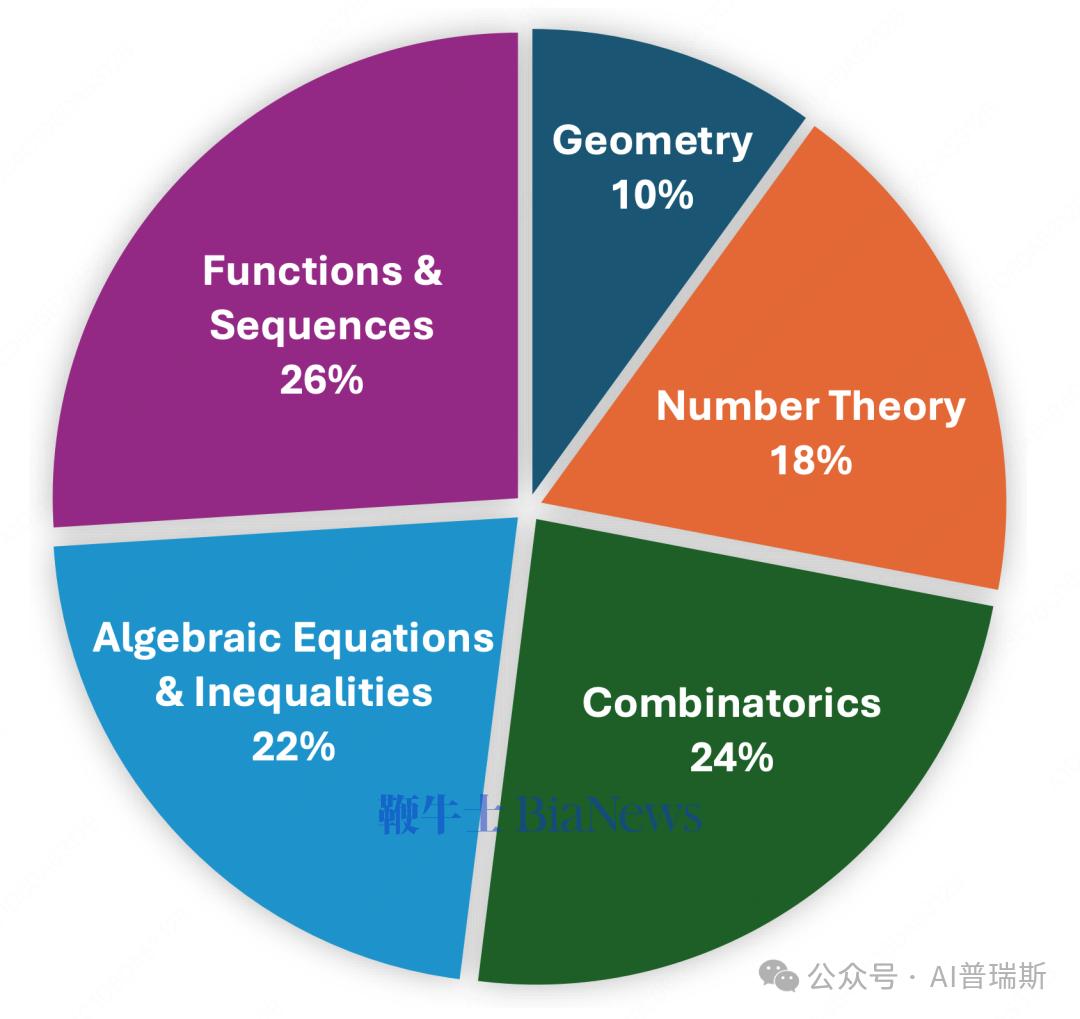
覆盖五大数学核心领域,推理链远超 AIME
AMO-Bench 的 50 道题覆盖代数、几何、数论、组合、函数与数列五类奥赛核心主题。与 AIME 等题库相比,AMO-Bench 题目的解题链条更长,需要构建复杂逻辑链,模型输出长度普遍达到原 benchmark 的数倍。
LongCat 发现:在 AMO-Bench 上,模型答案长度越长,得分越高,说明模型必须投入更多推理步骤才能接近正确解。
自动化评分准确率达 99.2%,大规模评测可真正落地
针对不同类型答案(数值、集合、表达式、描述性),AMO-Bench 采用多种评分策略,包括:
数学等价判定(Math-Verify)
LLM 多轮打分(majority voting)
实测准确率高达 99.2%,可以在不依赖人工批改的情况下完成大规模评测。
评测结果:头部模型“全军覆没”
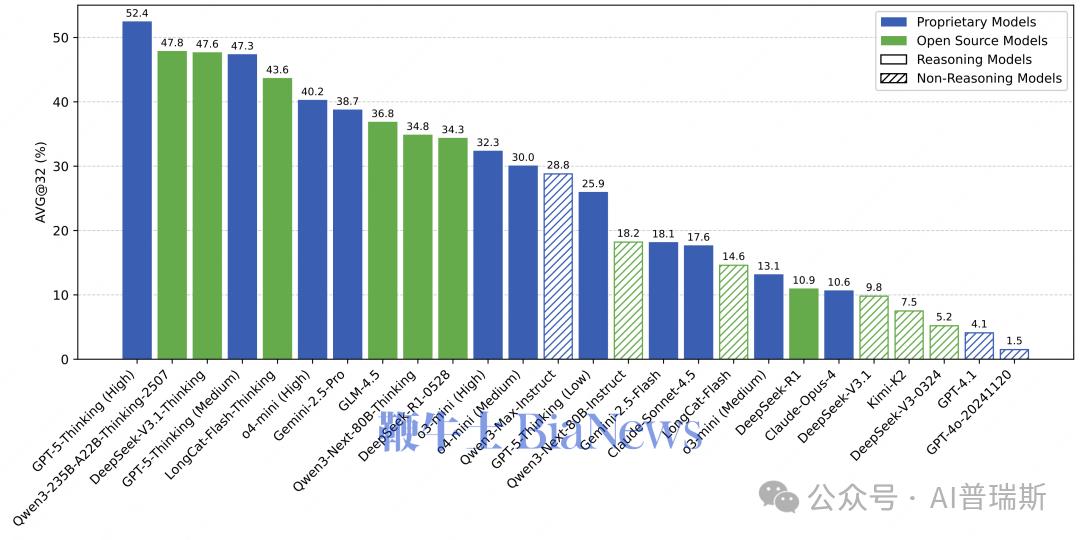
LongCat 对 26 个主流模型进行了全面测试,结果显示:
闭源推理模型最好,但仍远低于满分
GPT-5-Thinking(High)最高:52.4%
其余闭源模型多在 30–45% 区间
开源阵营虽然差距仍在,但追赶迅猛
Qwen3-235B-A22B-Thinking-2507:47.8%
DeepSeek-V3.1-Thinking:47.6%
两者均已超越多个闭源中量级模型。
Test-Time Scaling 依旧有效,但代价巨大
AMO-Bench 表明:模型愿意输出更多步骤(更多 tokens),正确率就能显著提升。
例如:一些 SOTA 推理模型平均输出量超过 35K tokens,同一模型正确率与输出长度呈“对数线性增长”曲线
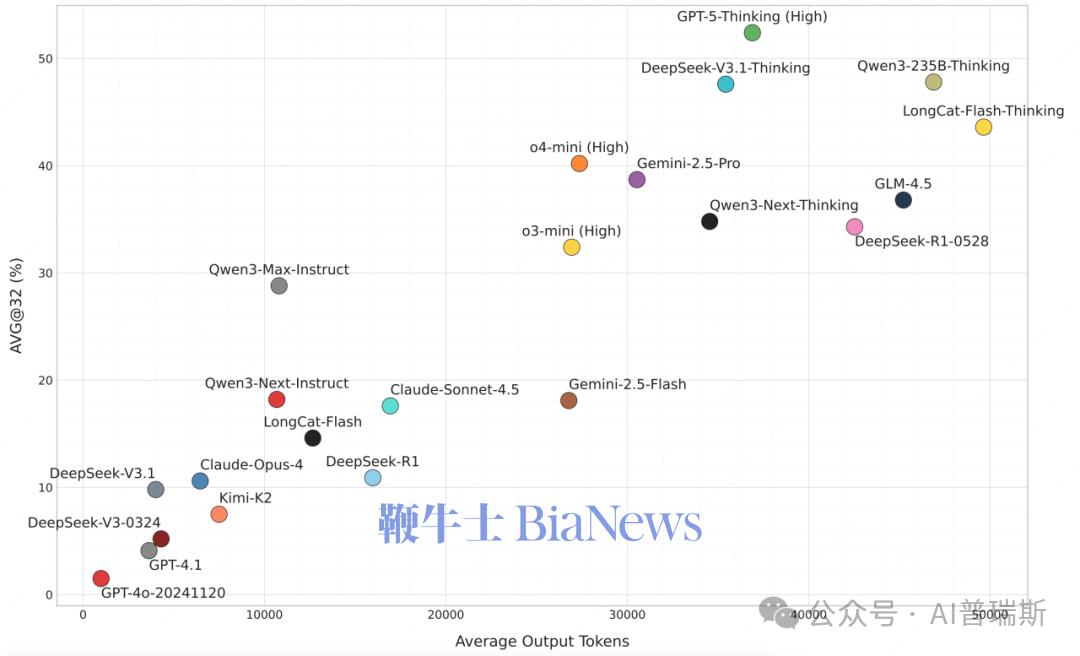
这验证了:
在数学推理上,“算得多”真的能“算得对”,但代价是极高的推理成本。
Pass@32 显示模型仍有巨大潜力
虽然单次正确率并不高,但多次尝试的 Pass@32 指标显示:
GPT-5-Thinking(High)等模型可达 70%+
说明大模型内部仍然具有“隐含”的正确解路径,只是一次推理未必能稳定走到终点。
AMO-Bench 的意义不仅是“难”,而是:
重新建立了数学推理评测的天花板;
让模型间差距重新拉开;
避免了数据污染;
实现了高可信度自动化评分。
给多家机构提供了真正能“逼出推理能力”的训练与评估工具。
LongCat 团队也表示将长期更新 AMO-Bench,并持续建设更通用、更高阶的“推理能力测试集”,推动大模型在推理领域不断演进。
AIME 时代的“高分假象”正式被打破。AMO-Bench 把大模型从舒适区一把拽回现实世界。(转载自AI普瑞斯)
更多AI资讯请点击:http://www.aipress.com.cn/
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



